

A Panoramic View of (One Small Slice) of Cybersecurity Data Science

4 Conferences. 224 Presentations.
An observer can be forgiven for believing that cybersecurity, data science, and especially cybersecurity data science are immature fields. The cybersecurity field is nascent enough that the National Security Agency (NSA) sponsors the Science of Security Initiative (see their annual best-paper competition) to explicitly “mature” this area of research. Data science — a field so wide-ranging that I hesitate to offer a definition — is arguably even less mature than cybersecurity. If cybersecurity is a young adult, then data science is a wide-eyed middle schooler. So, how can the field of cybersecurity data science move towards analytical adulthood? One step in the right direction might involve some reflection on recent developments. For instance, what are the topic areas within this field? What research methods are commonly employed? What methods are paired with what research areas? And, most tentatively, what explains any patterns of research activity?
This blog post is my modest attempt at such a survey of recent work in cybersecurity data science. It’s not definitive. It’s not rigorous. It’s not comprehensive. It is more than I have seen elsewhere and it might, depending on your taste, even be considered fun. This post measures and compares the prevalence of different topics versus research methods within this field based on an examination of recent presentations from four cybersecurity conferences. The findings include:
- Supervised machine learning on malware (malicious software) is the modal topic-method combination.
- Network traffic analysis is a thriving sub-field, although supervised machine learning has been less common for network traffic analysis, potentially because of dataset privacy issues.
- Reinforcement learning is employed relatively rarely compared to other methods.
- The field has many topic areas (at least 60) and a variety of methodologies (more than 20).
In short, it’s a healthy and growing field and the recent ferment suggests that that there are still many questions left unanswered and research projects left undone.
A Dataset of Conference Presentations
I gathered data from four conferences where the presenters and attendees would likely agree that many presentations concern cybersecurity data science. See table 1 for a summary of this conference presentation data. Because several of these conferences started within the past five years, there are missing years for some conferences.
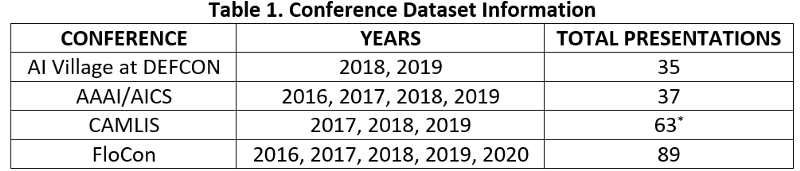
More typical artificial intelligence and machine learning conferences — such as the International Conference on Machine Learning (ICML), Conference on Computer Vision and Pattern Recognition (CVPR), and the Neural Information Processing Systems annual meeting (NeurIPS) — were excluded because few, if any, presentations at these forums focus on cybersecurity. The absence of cybersecurity-focused presentations at these premiere conferences is at least partly due to the methodological and theoretical focus of these conferences. Admittedly, if this analysis was to be comprehensive, relevant presentations from Black Hat, the European Conference on Machine Learning (ECML), RSA, USENIX conferences, and many more ought to be considered. This blog post should be considered only a tentative first attempt.
For each presentation, I extracted the authors, author institutions, conference, and year and then made a subjective (but hopefully consistent) judgement about what topics the presentation covered and what research methods the presenter employed. The topics and methods emerged organically while I read or watched the presentation or presentation’s abstract. I apologize in advance to any member of this community who feels that I have misrepresented their work. (Feel free to submit a pull request here.)
Admittedly, this method has many drawbacks. Some might prefer a more typically “data science” approach using natural language processing using the text associated with these presentations. Other researchers might also prefer to focus on patents, open-source code repositories, or arXiv papers. There are many potential alternative approaches.
Top Topics, Methods, and Institutions
Each presentation was assigned one or more topics. Each topic was then grouped under one of three topic area categories: data collected for presentations that focused on a particular security-related data type, cybersecurity area for when the topic concerned either a threat vector or defense mechanism or site of cybersecurity activity, and methodology for when the presenter focused on a broad methodological issue. These categories (and the topics within them) are not meant to be final, merely helpful. Other researchers using other approaches will create different conceptual groupings. Table 2 presents the top six topics within each of these three categories. The absolute number of presentations associated with a topic are less important than the relative frequency of topics.

The data collected category and specifically network traffic and malware represent the largest share of presentations — perhaps unsurprising given that any research or application will be heavily shaped by its data source. The prevalence of adversarial learning is consistent with the field’s emphasis on designing systems robust to attack from thinking enemies. I’ll return to the popularity of malware research later.
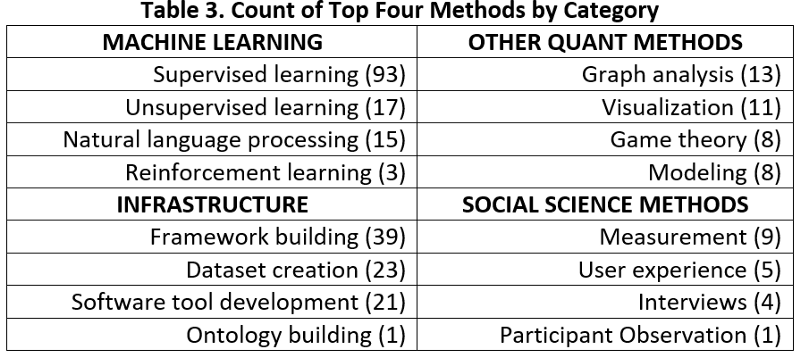
Additionally, all presentations were matched with one or more research methods grouped under a methodological category. See table 3 below.
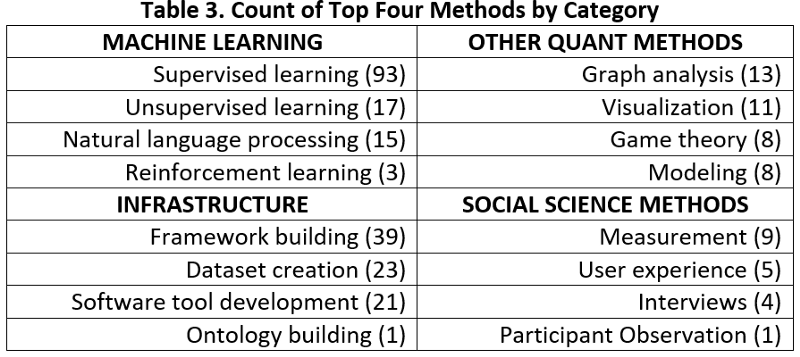
Machine learning refers to methods that use pattern recognition and inference to teach computer systems to perform a task (admittedly many other definitions are possible); other quantitative methods deal with more traditional forms of mathematical analysis; infrastructure involves those research tasks that are foundational to a research field, and social science methods indicate those methods traditionally associated with the study of human behavior. I should note that my placement of natural language processing (NLP) in the machine learning category is awkward; NLP need not involve machine learning, though it frequently does, and therefore placing it in “machine learning” or “other quantitative methods” was a toss-up. Table 3 presents the top four methods by methodological category. Supervised machine learning — the learned mapping of input to a category or value, given labeled data — far surpasses all other methods in frequency. One reason for this trend could be recent advances in “deep learning,” one powerful form of supervised machine learning involving neural networks. There are other methods too, including infrastructure work enabling further scientific research and even a few applications of social science to this field. Surprisingly, reinforcement learning — the form of machine learning associated with Google Deepmind’s superhuman AlphaGo software and arguably one of the more exciting lines of machine learning research — is used only three times. This finding deserves further explanation by future research, but one reason could be the difficulty of realistically representing the environment and decision space of cyber defenders and attackers.
The collected data also includes a list of the home institutions associated with each presenter or group of presenters. Table 4 presents the number of unique presentations with which each institution is associated. Only institutions connected to at least three presentations are included.
Large cybersecurity companies or companies concerned with cybersecurity dominate the list, though two federally funded research and development centers (government-affiliated research organizations) also have a prominent place.
Topic-Method Combinations
Readers might also be curious about the intersection of particular topic areas and research methods. Figure 1 is a heatmap with the top seven topic areas along the vertical axis and the top seven research methods along the horizontal axis.
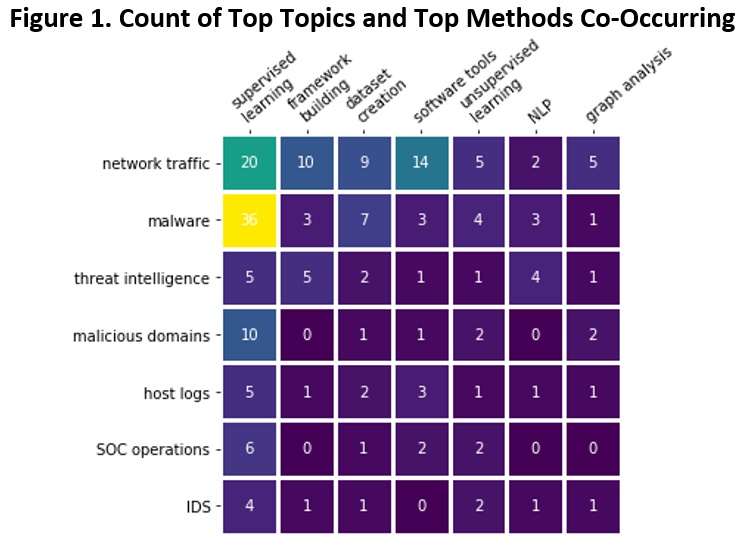
Presentations about malware using supervised learning are the modal topic-method category. This might not be surprising given the recent rise in the popularity of machine learning-based antivirus software and the companies that sell this software. Additionally, the active open-source publishing on malware by researchers like Joshua Saxe and Hillary Sanders of Sophos (see his high-quality Malware Data Sciencebook) or Blake Anderson of Cisco makes this area relatively approachable. But perhaps most importantly (and I offer these thoughts only as hypotheses) supervised learning research on malware is prevalent because there are large, labeled datasets of benign and malicious software. And lest the reader concludes that these conditions are sufficient for success, the very collection of these labeled software datasets is made possible by a series of permissive factors: the availability of large datasets of known benign and malicious software, the relative ease of labeling software as benign or malicious, the lack of security and privacy issues associated with software datasets, and the ability of machine learning models trained to recognize malware to transfer from context to context with at least moderate success.
These conditions might be found in other cybersecurity data science topics areas outside malware, but there will likely be skeptics and a variety of research obstacles. For instance, network security researchers Robin Sommer and Vern Paxson have made the theoretical case that machine learning-based network intrusion detection systems will struggle to transfer from context to context given the stupendous heterogeneity of network traffic. In a separate article, Vern Paxson and his co-authors also discuss the difficulties of anonymizing and publishing a network traffic dataset in order to address a reasonable set of security and privacy concerns. Of course, there can always be large-scale research efforts to address these challenges — see this call for creating the research infrastructure to apply machine learning to the mundane tasks of a security operations center — but such efforts require many researchers, money, and time.
Topics and Methods by Conference
Some readers might suspect that there is a lot of variation from one conference to another. For instance, the Artificial Intelligence for Cyber Security workshop (part of AAAI) tends to have more presenters from academia compared to the Conference on Applied Machine Learning in Information Security (CAMLIS), and FloCon tends to have more presentations on network traffic given its historical focus on this topic. To understand the differences and similarities among the conferences, Figure 2 uses a heatmap to indicate the frequency that the top topics are addressed across the four selected conferences.
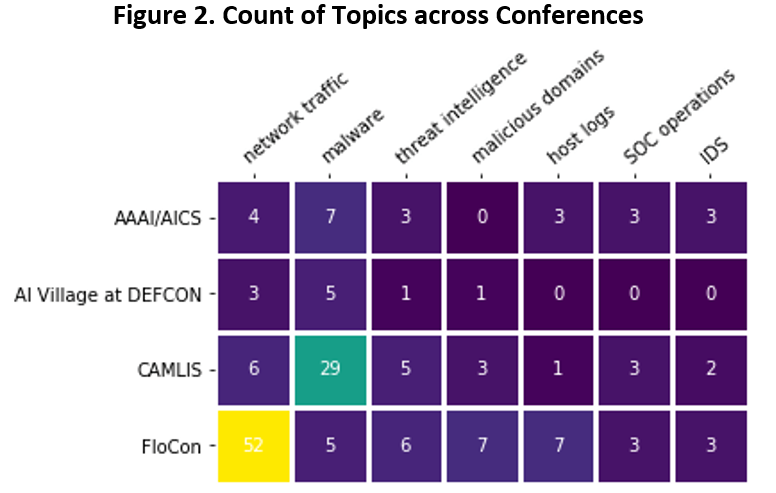
FloCon is indeed the site of the most network traffic-related research; CAMLIS has a noticeable focus on malware, potentially a reflection of the use of the Endgame Malware Benchmark for Research (EMBER) dataset at this conference. The AI Village at DEFCON has relatively low numbers in these topics because its mission focuses on the broader “use and abuse of AI,” not just cybersecurity.
Figure 3 visualizes the intersection of the top research methods and each conference.
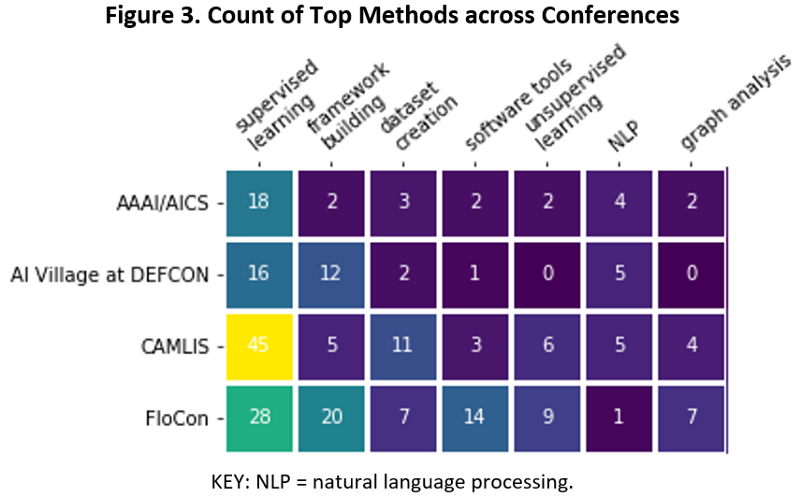
Supervised learning is the most common method at all four conferences. CAMLIS appears to be a particularly productive forum for researchers creating datasets and FloCon for software tools.
Growing Pains for Cybersecurity Data Science
This cataloging has revealed a field in ferment. There are many topic areas and many methods, although there are definite sub-areas of intense activity such as malware and supervised learning. These findings seem congruent with the forthcoming research of Scott Mongeau in which he interviews 50 cybersecurity data science practitioners and finds a thriving, if nascent, community. Future research will need to move beyond cataloging and to assessment, making judgments about the extent to which different areas and methods of this field are promising. To be sure, the Institute for Defense Analyses and the Johns Hopkins University Applied Physics Laboratory (among others) have done related reviews, here and here. However, these summaries have so far produced findings that are hard to parse. Importantly, any research summary should also try to explain the relative successes and failures across different sub-fields of cybersecurity data science. Until there are more and clearer assessments, this lack of reflection will be one more reason that cybersecurity data science will continue to exist in this awkward developmental stage, growing but not yet grown, and more promising than proven.