


IQT Labs recently audited an open-source deep learning tool called FakeFinder, that predicts whether a video is a deepfake.
We organized the audit around the Artificial Intelligence Ethics Framework for the Intelligence Community. And in previous posts, we discussed our audit approach and dove into the Cybersecurity and Ethics portions of the audit. In this post we describe how we tested for bias in FakeFinder’s underlying models, work we completed with our partners at BNH.AI.
In short, we bias tested two of FakeFinder’s detector models — Selimsef and NTech. The results of this testing indicated potentially concerning adverse impact ratio and differential validity scores for model predictions between protected classes (e.g., race, gender). We recommend
- taking steps to mitigate this bias; and
- bias testing FakeFinder’s additional detector models.
Before detailing our results and recommendations, we explain the approach that led to those conclusions.
Why test for bias?
FakeFinder’s models were trained on videos of human subjects’ faces. The use of biometric data in faces directly encodes protected group information, such as skin color or features associated with biological sex, into the data themselves. Unless explicitly addressed by the model developers, this tends to make model performance highly dependent on facial features that relate to protected class categories.
We anticipate that FakeFinder could be used to predict whether videos containing human subjects are fake and to inform actions related to these videos, or potentially, their subjects. If FakeFinder’s detector models were biased with respect to protected classes (i.e., race or gender), this could lead to biased predictions, which could lead to discriminatory outcomes.
At the outset of our audit, we had reason to suspect that this was a concern for FakeFinder’s detector models. In April 2021, several researchers at Facebook released a paper on arxiv called Towards measuring fairness in AI: the Casual Conversations dataset, in which they wrote that their evaluation of the top five winners of Facebook’s DeepFake Detection Challenge (DFDC) revealed “…that the winning models are less performant on some specific groups of people, such as subjects with darker skin tones and thus may not generalize to all people”.
As bias and fairness testing is a current (and active!) area of academic research, we were unsure of the best approach to use to evaluate FakeFinder’s detector models. To understand current best practices and legal standards, we collaborated with external counsel at BNH.AI, a D.C.-based law firm that specializes in liability and risk assessment of AI tools. The firm’s founders, Andrew Burt and Patrick Hall, advised us on a legally defensible methodology for bias testing, based on an analysis of how existing case law informs threshold values for determining “disparate treatment.” BNH.AI then conducted a battery of technical bias tests on two of FakeFinder’s detector models, using a subset of the DFDC preview data.
The steps we took.
Here is a summary of the steps we took during this portion of our audit:
- Reviewed the Model Cards for each detector model. (*Note: these were created by the IQT Labs FakeFinder development team.)
- Generated a Datasheet for the DFDC dataset
- Manually labeled a small subset of the DFDC preview data with demographic labels corresponding to baseline legal categories for protected classes: East Asian, Black, South Asian, White, Female, and Male. We understand that this step may have introduced another source of bias. Additionally, it is important for us to clarify that the results of our bias tests are based on perceived demographic (protected class) labels, and that these labels may or may not match how video subjects would self-identify. Ideally, we would have incorporated additional perspectives from a more diverse team as part of this labeling exercise. Although the testing we did — and the classes we used – are far from comprehensive, we stand by our results as an important starting point.
- Identified a battery of three bias tests:
- Adverse Impact Ratio (AIR), the rates at which faces in protected groups are detected as fakes, compared to faces in a control group. For the control groups, we used White for race and Male for gender.
- Differential Validity, a breakdown and comparison of system performance by protected class.
- Statistical Significance, t-tests on the differences in system outcomes (true positive model scores) across protected and control groups, using a two-tailed 5% test of statistical significance.
- Ran these tests multiple times for two of FakeFinder’s detector models — Selimsef and NTech. We found no precedents for bias testing models trained to detect the “face swap” manipulation, which can result in the face of one person transposed onto the body of another. As a result, we were unsure about whether to concentrate on the faces or the bodies of people in the videos . Erring on the side of thoroughness, we tested the Selimsef model four times, treating source video faces separately from source video bodies, using both training and test data. When the results were similar for faces and bodies, we tested the NTech model by looking at faces only.
- Identified threshold values to help interpret test results. From BNH we received the following guidance: “We typically look for at least a ratio of greater than 0.8 (such that no less than four fakes are detected for individuals in each protected group for every five fakes detected in the control category), in line with the legal standard, typically referred to as the ‘Four-Fifths rule.’ (4/5th)”
- We recommend repeating these bias tests for the other four detector models in FakeFinder, in order to gain a more comprehensive understanding of aggregate bias with FakeFinder’s predictions.
What we discovered.
Based on the approach described above, BNH concluded that the DFDC preview dataset was fairly balanced in terms of outcomes across demographic groups. They explained to us that “the number of real and fake videos within a demographic group appeared to be randomly distributed, as opposed to correlated to demographic group, which can help to minimize bias in models that are trained from such data.”
Bias test results for the Selimsef model are summarized below. We highlighted results that are concerning from a legal perspective in red. Results that meet legal thresholds but are still concerning from a bias/fairness perspective are highlighted in yellow.

For the Selimsef model, one Adverse Impact Ratio (AIR) result failed to reach the 4/5ths threshold (S. Asian-to-White) and we suspect this is related to an insufficient number of examples in the dataset. The model also presented out-of-range results for false positive and false negative predictions, indicating that the model is more likely to be wrong for protected classes than for whites, and wrong for males as compared to females. These results are ethically concerning, despite being largely untested in regulatory or litigation settings.
For this model we also saw that predictive accuracy decreased sharply for the test data (compared to the training data), indicating potential overfitting problems in the model. However, since accuracy dropped across all groups, we did not see any indication that bias was worse in the test data. All t-test results appeared within acceptable ranges, but this result can be deceiving, as statistical significance can arise from the sample size used for testing.
Results for the NTech model are summarized below.
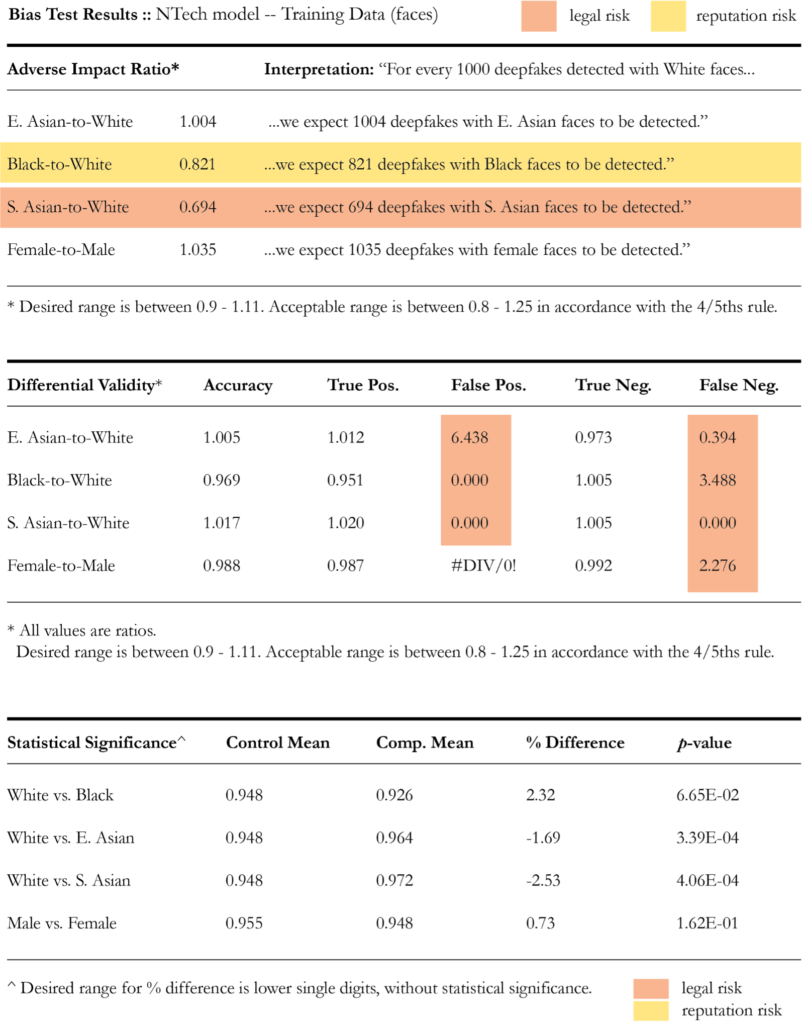
This model also exhibited one AIR result (S. Asian-to-White) that failed to reach the 4/5th threshold and we suspect the same cause. The NTech model also presented out-of-range results for false positive and false negative predictions, indicating that the model is more likely to be wrong for protected classes than for whites. For example, E.Asian faces experienced 644% of the false positive rate that White faces experienced. For the training data, t-test results were within acceptable ranges, but results were problematic for test data — a 10.67% difference in the true positive scores for White and Black faces and an 11.08% difference in the true positive scores for males and females. (Note: only training data results are pictured in Figure 5.)
What we recommend.
The initial findings by BNH to quantify bias in the Deepfake Detection Challenge winning models present a launching pad for more detailed analysis of causes and mitigation strategies. This work highlights potentially concerning adverse impact ratio and differential validity scores for model predictions between protected classes (e.g., race, gender). And based on these findings we strongly suggest testing the other four models utilized by FakeFinder to see what biases exist. Additionally, we think it could be useful to investigate potential methods of remediating bias in FakeFinder’s detector models, for example, by tweaking the loss function.And finally, we recommend that models are tested for bias on a regular basis while in use to ensure that changes to the underlying infrastructure or exposure to new data don’t inadvertently introduce additional biases.
There are several ways that bias can be introduced into a machine learning model. As such, it is important to have a rigorous method to assess model outcomes to ensure fair treatment. Today, bias testing is a nascent space, and regulatory and legal standards around model accountability are vague (when they exist at all). As a result, in determining thresholds for acceptable outcomes, we borrowed from areas — like housing and fair lending — where there are established standards. However, looking ahead, we see a clear need for additional standards and codified methods that can help to make fairness and bias testing a standard part of model development.