

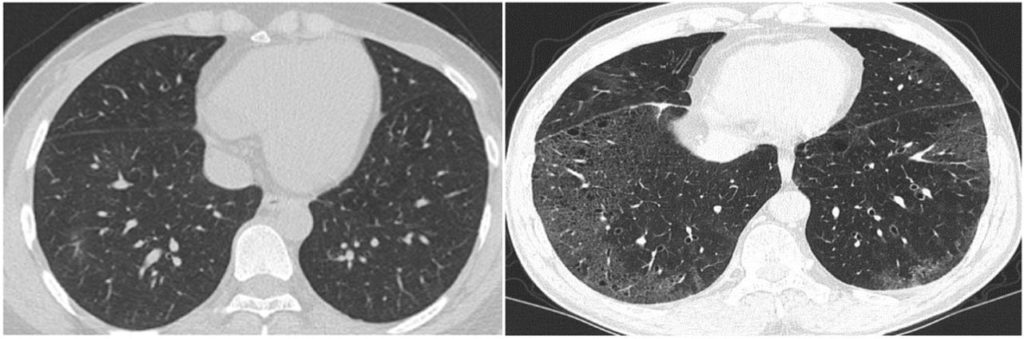
The picture above shows images from the COVID-CD-Dataset — what’s the difference between the two CT scans shown? To the trained eye, the image to the right is a scan of a COVID-19 patient’s lungs, while the image on the left is COVID-free. While hospitals have been relying on doctors to determine these CT-scan distinctions manually throughout the pandemic, a growing body of research is also investigating applying computer vision to these types of biomedical classification tasks.
Machine learning for biomedical image classification has been around, long before the coronavirus became a household name. People have been trying to automate high-level tasks such as lesion detection and diabetic retinopathy detection, as well as more low level challenges such as detecting cervical cancer cells or even different shapes of red blood cells. While recent successes, such as Google’s approach towards breast cancer detection, have seemingly found the holy grail of outperforming humans at the same task, most radiologists (and biologists) will still have a job in the near future. Many, if not most, of the potential real-world applications of computer vision to biomedical imagery tasks suffer from either small labelled dataset sizes, or difficultly in agreeing on what the correct label is for an arbitrary image. Sometimes, it’s both.
In this blog, we share our lessons learned exploring such a challenging computer vision problem in the biomedical domain. Here at IQT Labs, we’ve recently collaborated with Emulate, Inc. on a biomedical computer vision challenge: using machine learning to automatically classify the health and viability of liver cell (hepatocyte) cultures on Organ-Chips. Manual grading of cell morphology to determine the health of a cell culture is still an important readout in applications such as drug toxicity, and being able to automate this step without the need for a highly trained biologist will expedite and scale these experiments. Consequently, they would be able to generate faster insights into how human organs may respond to chemicals, medicines, and foods. Currently, we’re not aware of any other work trying to classify hepatocytes on such a medium, making this a particularly unique and exciting dataset for IQT Labs to work with.
Labeling biomedical images is often challenging
Of course, biology is complicated. Human liver cells are naturally sticky and pick up debris. Determining if healthy, viable cells are growing on the organ-on-a-chip medium is a nuanced task, even for trained experts. Consider the two phase-contrast images in Figure 2 below:
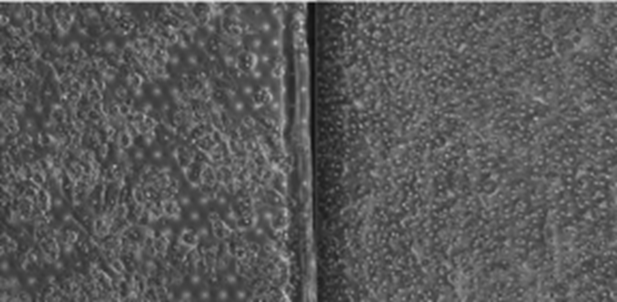
Sometimes, it is easy to tell a healthy culture (on the right) from a decaying one (one the left). We’d know to discard the latter immediately. Other times the distinction is more subtle as in Figure 3 below:

Once again, the unhealthy cell culture is on the left in the above image, where a trained eye notices more debris/dead cells layered on top of the more viable hepatocytes attached to the membrane. The cellular junctions (where one cell touches another) are fuzzier, too.
Relying on trained humans to rate such images, even though it may not take them much time, does not scale well, because training people to make these distinctions is not easy. We wondered, given the existing image datasets Emulate had collected, would it be possible to train a classifier to automate this process of cell culture labelling? Even though we were faced with the known obstacles of only a few hundred images, we anticipated that machines might have just as tough a time seeing the distinction between the two images above as untrained humans would. We were optimistic that we could train a classifier to, at least, triage these hepatocyte cultures for human inspection. For example, if we could obviate the need to manually examine even half the images in the user workflow, or match the human accuracy for labelling these cell cultures correctly (~85%), sparing biologists from all or part of this process could be feasible.
Lesson learned 1: If it’s hard for humans to learn, it’s hard for machines to learn
We had access to about 750 black and white, phase-contrast images of hepatocyte cultures-on-a-chip, as shown in the examples above. Unfortunately, we quickly realized that for the untrained data scientist, the difference between good and bad cell cultures was often more subtle than irrelevant differences within one of these two classes:

For example, all three images above in Figure 4 were labelled as unusable cell cultures by biologists but have more notable differences with each other than with good examples. Whether an image above looks more like tadpoles versus divets depends on the lighting of the phase microscope. How well would a machine learning classifier learn to ignore these differences, while seeing the distinction above? Given that our initial attempts at modeling cell cultures (around 70% accuracy) with this kind of microscopic illumination didn’t even match our human baselines: not well.
We tried to build a classifier to distinguish between the three “styles” of lighting we saw above first, and then train another classifier to predict good vs bad within each of those image sets, but this approach didn’t work either. Various transfer learning techniques, both from ImageNet-based models, as well as a model we built off of 50,000 images of cells from this COVID-19 dataset, yielded few, if any, improvements. Similarly, image transformations, such as binary thresholding, erosion, and CLAHE enhancement (see example transformations below in Figure 5) also didn’t help match the models to human performance:

Even the models’ high-confidence predictions were not usable to triage cell cultures for human inspection.
Lesson learned 2: Sometimes less is more
Fortunately, Emulate was able to provide us with a second set of bright field images (Figure 6) that were a lot easier for non-experts to label correctly; color allowed easier visibility of extra-cellular debris as brown, and there was no longer an issue of microscopic illumination variance within the good vs bad classes:

Although this dataset had roughly half the images of the earlier black-and-white one, we were able to generate a classifier that exceeded human accuracy overall (at least on our test set), and its high-confidence labels could be used to triage new images for inspection. One of the other desirable properties of this second dataset was also that good vs bad images were roughly equally balanced, while in our initial dataset, there was a 1:3 ratio between good vs. bad images, which had to be manually corrected by trying to weight samples when training those classifiers. Even though we had half the images of our first dataset – roughly 200 per class – we were still able to dramatically outperform those initial classifiers due to the higher quality of this data.
Open question: Generalization?
Before we start freeing biologists from grading tasks, however, we must admit that the ability of our models to generalize to new data is still an open question. While we used cross-validation across multiple trials to measure how sensitive models might be to specific subsets chosen as training data, in this dataset there are roughly three photos per chip. In the future, having more detailed chip metadata will ensure that we’re not testing and training on the same chips, in addition to the same images.
We used color as one of the ways to separate chips (and their associated images) into test and train sets. We assumed that images from the same chip would probably be the same hue of blue-to-green. For example, the images below were likely to be from different chips:

While we suspect that these three images might be from the same chip, given how similar their background blue is at the top and bottom of each image (where no cells live):

As a sanity check, we manually split our dataset into a train and test set by reserving the greenest images for testing only. We observed a ~10% drop in performance with such a split but weren’t sure if it was due to actually ensuring the same chip didn’t end up in train and test sets, or just an unlucky choice of division on our part. Therefore, we took the average of all good and bad images (see below), hoping there would be no detectable differences, but given that the top and bottom background of good chips was greener than the bad ones, our splits may have been more biased than we’d like. Still, the classifier trained on this split matched human performance, and its accuracy on its high-confidence predictions was close to perfect, obviating the need for humans to manually inspect over half of the images themselves.

Whether or not our classifiers will generalize to images of new, unseen chips remains to be evaluated on more data. In the meantime, we’ve learned about the importance of planning ahead for machine learning in biolab workflows given that such ultra-small datasets are common in the biomedical domain, it’s important to collect representative images that:
- have a desirable balance between the classes;
- have metadata that can distinguish between bio-specific artifacts like multiple images being taken from the same chip; and
- take advantage of any technology that helps naive humans (and therefore, machines) tease apart differences between classes (relying on color bright field images over the black-and-white phase contrast ones).
Under such scenarios, we learned it was entirely possible to build useful classifiers, with the caveat that generalization must always be evaluated on new data, especially with the general danger of overfitting to ultra-small datasets.
Thanks to our colleagues, Felipe Mejia, John Speed Meyers, and Nina Lopatina for their help writing this post.