


Summary of 30 biomedical papers from this year’s conference
In our previous blog post on Bio-NLP papers we surveyed from the Annual Meeting of the Association for Computational Linguistics (ACL2020), we found that at least half were using BERT-based models to improve upon the state-of-the-art. Even though BERT is a superior choice for a wide variety of natural language processing tasks — and specialized pre-trained flavors, such as BioBERT, SciBERT, and ClinicalBERT are available — many models still benefited from incorporating outside biomedical knowledge bases and capitalizing on the hierarchical relationships between biomedical keywords. In this post, we shift away from exploring the machine side of biomedical NLP, and focus on increasingly more human-centered concerns:
- Information extraction: How do researchers propose to effectively search biomedical texts for relations and evidence where a complicated set of concepts needs to be effectively found and justified from academic literature and/or Electronic Health Records (EHRs)?
- Explainability: In a field where accuracy can influence a life-or-death decision, how do we improve interpretability and explainability of machine learning models?
- Evaluation: How do we obtain new datasets, benchmarks, and evaluation methodologies over a domain corpora that is often small and subject to privacy issues?
In addition, we share our conclusions from “attending” the conference, where we left wondering: given the often limited datasets we’re dealing with, what is the real-world usability and adoptability of these NLP tools we found? As promised in our previous post, we analyzed the state-of-the-art results reported in these ACL papers to get a holistic view on how many could realistically be adopted in practice, which we share at the end of this post. Let us start by exploring how to improve biomedical document search.
Biomedical Relation Extraction, Search, and Q&A
Biomedical NLP is complicated not just by challenges in multi-task classification, but also by higher order requirements for fidelity and the need to avoid harm towards patients (including those with incorrect or missing data). For example, what if an algorithm missed crucial information, and people got sick? What if a physician missed a potential life-saving treatment when trying to research medications for atrial fibrillation? With so many structured synonyms that often can be considered the same by a human, mining information from biomedical articles must focus on condensing concepts to be useful, rather than just listing out all needles-in-the-haystack.
For this reason, many papers at ACL focused on how to better mine information from biomedical articles through relation extraction (e.g., chemical-disease, gene-disease, gene-gene, etc.). For example, Paullada et al. encoded dependency paths connecting biomedical entities into neural word embeddings to improve relationship retrieval and literature-based discovery:
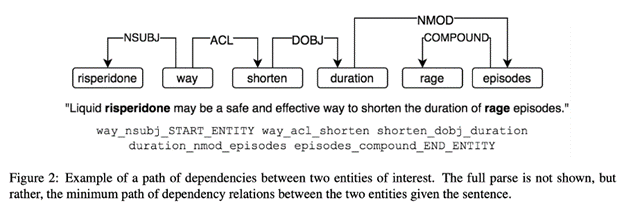
Such dependency paths are a common NLP topic, frequently used for grammatical relationship tracking; here, they are being used to solve biomedical analogical retrieval problems instead.
Amin et al. also focus on biomedical relations when they note that the position of entities in a sentence, and their order in a knowledge base, can encode the direction of their relation. They use this approach to reduce noise in distantly supervised relation extraction by extending sentence–level relation enriched BERT to bag–level (where a bag is an unordered sequence of sentences that all contain the entity pair) Multiple Instance Learning (MIL). ShafieiBavani et al. similarly note the long dependencies in biomedical entity (and event) extraction, which they tackle with multi-head attention, in combination with CNNs, to capture more local biomedical relations:
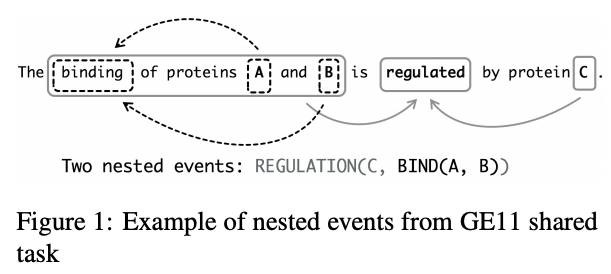
The ability to better extract relations from biomedical texts is especially useful when the format of what you’re looking for, such as a two entities {breast_cancer, neurofibromatosis} is in a sentence: “Best practice guidelines for breast cancer screening are not sufficient for the screening of neurofibromatosis carriers.” Often, however, the challenge of searching biomedical texts lies in how to supplement a natural language query. Modern search engines tend to only look for keywords in articles, often yielding thousands of results that still have to be manually curated to be useful. For example, Das et al. convert a query sequence into a more meaningful set of keywords for search using an encoder-decoder.
Some other information retrieval approaches we saw at ACL this year were a customized interactive search system and improving BERT-based Question-and-Answer by incorporating an auxiliary task of predicting the logical form of a question (which helps with unseen paraphrases). External knowledge bases were also used to supplement web-based document retrieval by displaying color-coded evidence scores for each document returned in a user search based on textual patterns in the background corpora that match the query.

Interpretability, Explainability, and Evidence
The approaches in the previous section attempt to improve biomedical literature-based information retrieval, which is vital for patient safety and health. As the web-based search engine above revealed, one way to reduce the risk of an incorrect recommendation is by providing evidence and/or explaining how the model arrived at its conclusions. For example, if a physician uses a system like a symptom checker to aid in making a diagnosis, she can be more confident in its recommendation if the tool provides a level of confidence in the automated diagnoses or illustrates why it might have ruled out other diseases.
Many papers at ACL this year focused on this important desire for machine learning decisions to be explainable and interpretable. For example, Wang et al. use global co-occurrence statistics to arrive at rationales, such as “may cause,” for entity relations predicted from EMRs (see below). Chen et al. balance accuracy and interpretability of automated text-based diagnoses for EMRs, through the use of Bayesian Network ensembles to help explain the prediction.
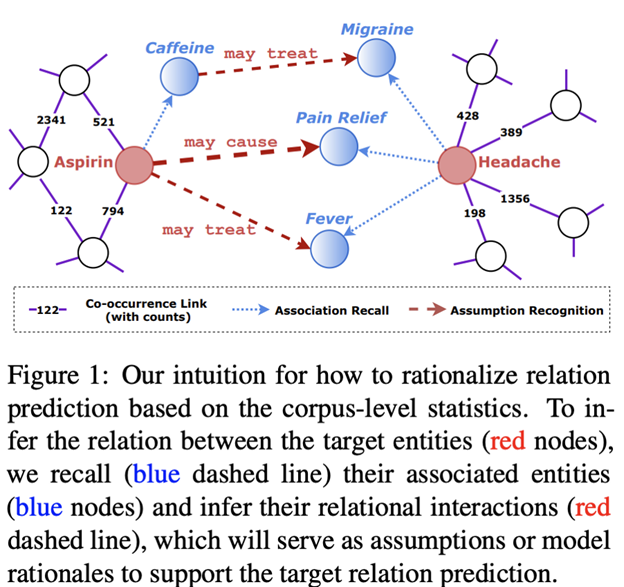
Meanwhile, Shing et al. sought to explain the effectiveness of crisis counselors’ texts by how they balance advancing the conversation versus backwards reflection, and Zhang et al. used attention and hierarchical time-based gain as evidence to prioritize reading Reddit users’ noisy posts for suicide risk. Evidence mining and mapping were also explored by Wang et al. in automatically extracting supplement-drug interactions (a problem that lacks labelled data), while Nye et al. use BioBERT to develop an automated visual evidence mapping extractor for randomized controlled trials.

Evaluation of BioNLP models
In discussing evidence and explainability of BioNLP approaches presented at ACL2020, we’ve arrived in the arena of human-computer interaction (HCI), having worked our way up from the starting point of this blog post where we discussed lower-level details of BERT-based word embeddings for machine learning. We will now discuss papers that focused on evaluation of BioNLP models and techniques, in addition to our earlier overview of new state-of-the-art models. Evaluation techniques for BioNLP tools deserve special consideration due to the complex requirements between correctness, completeness, and how humans are often able to easily forgive certain classes of errors.
As a baseline, some papers explored how BERT variants perform on existing baselines and datasets. For example, Wang et al. hypothesized that these large models may overfit in the low-resource setting of clinical semantic textual similarity, for which they suggested mitigation strategies, such as hierarchical convolution, fine-tuning, and data augmentation methods. Text similarity was also the focus for measuring the effectiveness of different multi-task learning with BERT-based models, along with relation extraction, Named Entity Recognition (NER), and text inference benchmarks.

Other considerations of model evaluation pose even more challenging metrics, which are arguably more important than textual similarity. Zhang et al. observe that summarizers of radiology reports may be trained to best overlap with human references (ROUGE scoring), but this does not guarantee factual correctness (see above). They propose a Factual F1-score to supplement ROUGE-1, -2, and -L scoring. Similarly, Nejadgholi et al. suggest that small gains in F1-scores for biomedical NER are ineffective measurements of accuracy because they look for exact matches, rather than considering benign mismatches, such as a hand-labeled entity and a predicted one having overlapping spans and the same predicted tag. Such Mismatch Type-5 errors, they point out, make up 20% of errors in NER evaluation but only 10% of this type of error is judged as unusable by humans. The authors propose to use a learning-based F1-score for NER evaluation by building a classifier that can approximate a user’s experience towards these Type-5 errors.
These two papers that propose more effective metrics for evaluating BioNLP models are particularly important, in our opinion, because they focus on a critical question: are these models currently usable in the biomedical domain, with its special boundaries around doing no harm to patients? We wanted to understand which of these state-of-the-art methods could be adopted in practice and mapped the details of the lift in metrics each paper reported in its abstract, conclusions, or first in their results sections. We had difficulty summarizing the each paper’s entire contribution to just a single number (or even a range), but the graph below is meant to convey a general sense of what kinds of scores and improvements are being discovered:
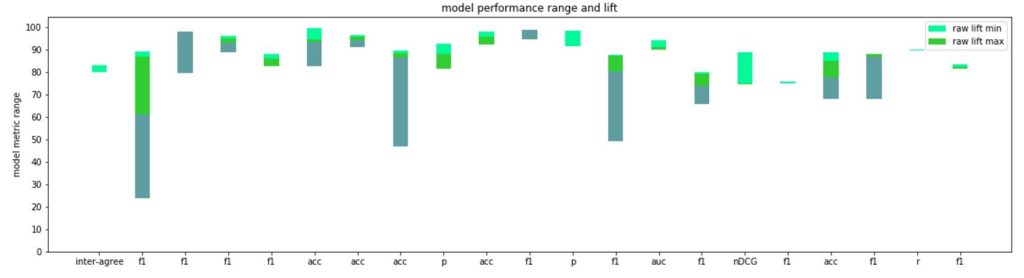
Each multi-colored bar represents the range of metrics reported in that paper for the novel model(s) proposed. For example, in the first F1-score range reported in the graph above (second column at left), across all benchmarks, was 0.24 to 0.89 (multi-colored green bar), with the smallest lift on a baseline benchmark being 0.02 (lightest green), and the largest lift 0.28 (lightest green plus medium green). The more light green you’re seeing, the more impressive the model was compared to state-of-the-art (in cases where no lift is visible, the papers established new benchmarks).
Such a comparison is inherently flawed, in that not all benchmarks are created equal, nor are the different tasks necessarily as sensitive to errors or improvements. Nonetheless, the average improvement over state-of-the-art where reported was likely around a 4–9% lift from baseline, while F1/accuracy and other comparable metrics (as opposed to something like ROUGE scores) ranged between 0.78 and 0.91 on average. Although each model must be evaluated independently, we’re left wondering how deployable these automated approaches are in the biomedical domain with these kinds of scores. Do they need to outperform humans? Specifically, researchers and especially regulators may want to think about what are acceptable ranges of model performance before applying these technologies to real-world patients who can easily be harmed by models that are wrong, overfit to their training data, and whose range and conditions of failure is not known.
Summary and Future Work for BioNLP Researchers and Policymakers
NLP in the biomedical domain has two main challenges that differentiate it from more general natural language tasks: 1) there is less room for error when dealing with patients and 2) current biomedical datasets are often small and/or noisy (due to abbreviations and synonyms).
Here at IQT Labs, we’re interested in advancing the state-of-the-art in deep learning tools as well as overcoming obstacles to real-world adoption of these novel ideas. After reading these papers from ACL, we wonder if a constructive way to move forward in the biomedical natural language space is by collecting (and pre-processing) more, and easier-to-machine-analyze data, in order for these state-of-the-art models to really shine?

Although several new datasets also were presented at this year’s conference (for example, BIOMRC, RadVisDial above, and a silver standard for MIMIC-III), EHRs are often more challenging to study, as opposed to biomedical research articles. EHRs, typically, are created by different healthcare professionals that are usually in a rush to help other patients. We like to remind ourselves as BioNLP researchers of our role to support efforts that obviate the need for a lot of the data pre-processing required to make good predictive models (such as biomedical term normalization). Further research into privacy-preserving methods also can help alleviate issues with data scarcity and potential overreliance on existing benchmark datasets.
The field of machine learning and NLP is relatively new, and we suspect that not enough attention has been given to update workflows in healthcare settings to standardize and simplify information entry. Focusing on creating novel datasets, rather than novel algorithms, might be a more effective way to increase performance, generalizability, and usability of future machine learning models. For example, structured radiology reports have been found to be more complete and correct than unstructured reports. Updating the tools and workflows that healthcare professionals use daily forces gathering and recording of cleaner, better data that not only helps patients in the short term, but can help supply NLP researchers with more digestible datasets to build models that are accurate and safe enough to be deployed back into clinical care.
Thank you to my colleagues Nina Lopatina, Ravi Pappu, and Vishal Sandesara