


Summary of 30 biomedical papers from this year’s conference
Didn’t have the time to read through the 30-plus biomedical Natural Language Processing (NLP) papers that appeared in the Annual Meeting of the Association for Computational Linguistics (ACL2020)?
No problem. We at IQT Labs present the highlights in this blog post. Our one-sentence summary? BERT is large, biomedical datasets are small (and fragmented), and we’re intrigued to explore how we can improve the real-world utility of the advances made in this domain.
ACL is one of the premier conferences on Natural Language Processing (NLP). In addition to the main program, there were several workshops: BioNLP, medical conversations, and even just-in-time COVID19 NLP. In this blog post, we only cover the biomedical papers from the BioNLP workshop and the main conference papers in our reporting and analysis. Overall, we found five main themes of active research:
- BERT, the state-of-the-art word embedding tool. Mostly to the tune of “we applied BERT to some biomedical problem/dataset and achieved state-of-the-art, if incrementally better, results.”
- Multi-label classification problems in biomedical NLP, that stem from the overlapping and/or hierarchical nature of diseases, medicines, and concepts in this field.
- Search, relation extraction, and evidence mining of biomedical texts, where a complicated set of concepts needs to be effectively found and justified from academic literature and/or Electronic Health Records (EHRs).
- Interpretability and explainability for a field where accuracy can influence a life-or-death decision.
- New datasets, benchmarks, and evaluation over a domain corpora that is often small and subject to privacy issues.
Here we cover the latest research presented in the first two of these areas. In our follow-up blog post, we’ll finish with the last three topics, paying special attention to our conclusions from “attending” the conference. First, let’s take a look at the exciting novel ways BERT is being applied to the biomedical domain.
Novel applications of BERT and its variants on biomedical documents
The 2018 introduction of Bidirectional Encoder Representations from Transformers (BERT) revolutionized NLP. If you’re unfamiliar with BERT, you should think of BERT as an extremely powerful model for generating context-aware embeddings for sequences of words. These BERT embeddings can then be fed into an almost unlimited number of downstream NLP tasks, such as making predictions about the quality of translations, question answering, improving Google searches, or token classification tasks like Named Entity Recognition.
To apply machine learning to natural language text, sentences are typically converted into a numeric embedding (vectors); BERT is a great option for this when you’re interested in preserving the semantic information found between words. Otherwise, older embedding approaches, such as word2vec, can still be quite useful if you’re less interested in capturing context, but related words having predictable similarities in their vector representations could benefit your approach.

However, being able to encode context, such as learning that the term melanoma was associated with the term sun damage earlier in the sentence/paragraph can be especially relevant in this domain. Therefore, in biomedical corpora, the text of academic articles is something we’d prefer to analyze at the sentence or paragraph level typically. Other documents, such as EHRs (see example above), medical keyword ontologies, or healthcare professional text message chats are often made up of sentence fragments, abbreviations, and phrases; context is often still important, but can be more challenging to mine from these examples.
These differences, for example between biomedical natural language and the text found in news articles or literature, pose additional challenges for this domain. Not only are state-of-the-art models like BERT less likely to yield dramatic results on problems without well-formed sentences, but deep NLP architectures like BERT are extremely data hungry. Given a lack of real-world biomedical training data available due to privacy concerns, researchers often use existing, open-source datasets (such as the over 50,000 intensive care unit stays in the MIMIC-III dataset). Nevertheless, this year’s conference had at least 15 papers discussing state-of-the-art results using BERT on biomedical natural language tasks.
One advantage of BERT for the biomedical domain is that it breaks up words into subword tokens in its embeddings, a feature that provides an advantage of when processing medical terms with frequent subword overlap, such as [hyper — ]/[hypo — ] and [— mia] in {hypertension, hypotension, hyperlipidemia, hypercalcemia,…}. Consequently, BERT-based models can perform better than whole-word models for biomedical problems with large domain-specific vocabulary and abbreviations, as one BERT-based paper that predicted punctuation and truecasing in doctor-patient conversations demonstrated.
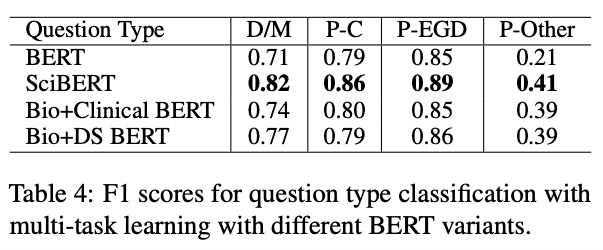
Researchers also commonly employ BioBERT, a biomedical pre-trained BERT-based model. BioBERT, and other specialized pre-trained models such as SciBERT (scientific text), ClinicalBERT (clinical text and/or discharge summaries), and even VetBERT (veterinary clinical notes), have been used to help alleviate the problem of small biomedical datasets for NLP (e.g., a few thousand clinical records) by leveraging existing models that were already trained on up to millions of biomedical, scientific, or clinical documents. For example, contrary to how BERT uses multiple tokens to represent the word colonoscopy, SciBERT encodes it in a single token. Ding et al. hypothesize that, consequently, SciBERT ends up with a better domain-specific vocabulary that can help in triaging electronic consults by urgency and question type:
Other research presented at ACL this year were able to achieve novel results using BERT embeddings. For example, Sotudeh et al. used a biLSTM on top of SciBERT to select salient ontology representations from the FINDINGS sections of radiology reports, to be combined with the IMPRESSION section that is trying to be summarized, observing a 2–3% improvement over the state-of-the-art. Koroleva et al. compared using three models, BERT, BioBERT, and SciBERT, to detect spin in the reporting of randomized clinical trials in academic articles; BioBERT achieved the best performance (over BERT and SciBERT) on many of their spin detection sub-tasks (with BioBERT’s F1 scores ranging between 0.88 and 0.97), although rules-based approaches were necessary for other sub-tasks where there was an absence of training data. ClinicalBERT embeddings shined during automated de-identification (removing personal information) from English discharge summaries, where Lange et al. found that anonymization has no negative effects on downstream concept extraction tasks:

Combining BERT with outside data to improve performance
Even powerful models like the BERT-based ones discussed above, especially those built with inadequate training data, can be supplemented by using novel features that were derived independently from the training documents. For example, the prototypical Kaggle Titanic competition, where data scientists are challenged to predict who survived the sinking, provides a dataset of names, ages, cabins, etc., of passengers. While a model can be built on this dataset alone, competitors that used an outside database tying names to their common genders, folding in presumed gender as an engineered feature, were able to do better when “women and children first” was a policy for evacuation, and therefore, survival.
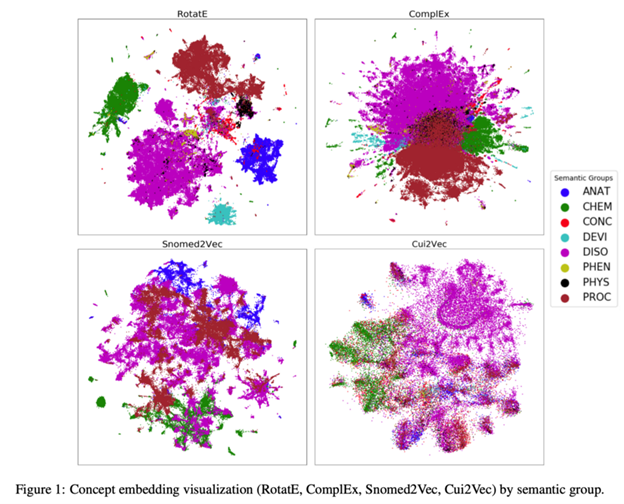
Embeddings. RotatE and ComplEx are both GraphVite models.
There were several deep-learning approaches that cleverly supplemented their BERT embeddings with additional features. For example, Dutta and Saha incorporate established protein sequence and structure, as well as BioBERT embeddings of biomedical articles, into a multi-modal predictor of protein-protein interactions that outperforms other strong baselines. Similarly, Chang et al. tackle how to best encode and evaluate knowledge graphs into embeddings for downstream BioNLP tasks (see above). They compare five flavors of the GraphVite node embedding framework against Snomed2Vec and Cui2Vec embedding models, recommending using the former in contexts where performance on link prediction, entity classification, and relation prediction.
Sung et al. outperform current state-of-the-art for normalizing biomedical synonyms (such as motrin and ibuprofen) — which helps improve downstream NLP tasks — by combining BioBERT for a dense representation of the word, along with a separate sparse input of synonyms generated using tf-idf, before learning weights and returning the highest-ranking candidate (see above). Xu et al. also focused on biomedical synonym normalization, using them to generate-and-rank synonyms from the Unified Medical Language System (UMLS) Metathesaurus. These synonym candidates, along with BioBERT, were used to treat the task as a question-and-answering system where the most likely synonym is to be chosen from a list of candidate concepts; they achieved several state-of-the-art accuracies with their approach (often nearing 90%).
Multi-label classification
Normalization of biomedical terms, that is, working around the problems of biomedical abbreviations, keywords, and their overlap was a common theme in BERT-based approaches we saw at ACL this year. Indeed, classifying biomedical text is often challenging, as multiple labels are required for the same document: having fewer categories makes it easier to train models, especially with limited datasets. For example, when referring to a paper about follicular papillary adenocarcinoma of the thyroid, any of the terms in the NIH MeSH keyword structure below could be used as keywords or class labels, as well as variants with the word thyroid:

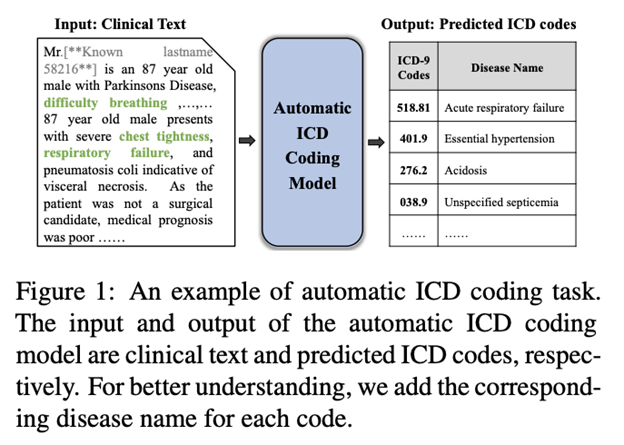
In the example above, it would be easier to train document classifiers if all of the effective synonyms above for cancer {neoplasm, carcinoma, adenocarcinoma, cancer} could be converted to just neoplasm. Extending this concept further, Yu et al. automatically mine keywords for biomedical articles by using a co-occurrence model of potential tags that is learned through Graph Convolutional Nets (GCN) along with Gated Recurrent Units (GRUs) that capture context features, outperforming the state-of-the-art baseline (a multi-channel TextCNN). Such an approach would automate the human keyword annotation MEDLINE articles would normally receive. Co-occurrence, along with code hierarchy, was also used to automatically mine ICD codes from medical records in another GCN model by Cao et al.:
With these superior keywords approaches in mind, the field can hopefully expand upon validating different models for multi-label classification.
Another type of common classification problem involves labelling the same text across different binary disease metrics, such as disease confirmation, temporality, negation, and uncertainty, rather than distilling similar diseases and symptoms into a single, meaningful ICD code. For example, Mascio et al. attempt to test different tokenization (SciSpaCy versus byte-pair encoding), other pre-processing (stemming, lemmatization, stopword removal, etc.), and word embeddings (Word2Vec, GloVe, FastText) on different classification algorithms (SVM, ANN, CNN, and RNN-biLSTM), along with BERT and BioBERT, across these four disease metrics. Word2Vec with SciSpaCy and bi-LSTM scored the best on all four metrics in the MIMIC and ShARe datasets used, even outperforming BioBERT slightly, as long as the biLSTM was configured to simulate attention on the medical entity of interest.
Classifying biomedical text, whether dealing with multiple labels or reasoning about disease status and uncertainty, hints at more obstacles exemplified in this field around human interaction with the results of these NLP models. For example, human generation of search queries , and the interpretation of model-based search results, challenges researchers to find better ways explain and evaluate these machine learning approaches within the special context of the biomedical domain.
Where to go next: usability of BioNLP advances
Next, we’d like to offer insights into improving the real-world usability of these novel approaches from the conference. We’re left wondering, specifically, how meaningful is an incremental gain of 0.02 in a F1-score reported in these papers given the often limited datasets we’re dealing with? How well would these models presented generalize? What is the real-world usability and adoptability of these tools?
To attempt to quantify such a metric, we decided to map the state-of-the-art results reported in papers we reviewed. We tried to obtain holistic view on how many of these models could realistically be adopted in practice, by compiling a list of the lift in metrics each paper reported in its abstract, conclusions, or first in their results sections. We will share these in our next post, along with papers from the remaining three themes (search, explainability, and evaluation) from this year’s conference that we have yet to discuss.
Thanks to my colleagues Nina Lopatina, Ray LeClair, Benjamin Lee, and Vishal Sandesara.