


IQT Survey Finds Widespread Trust-Based Code Reuse
Code reuse, the practice of creating new apps out of existing software components, is a major productivity multiplier. The idea originated with M. Douglas McIlroy who proposed ”mass-produced software components” at the 1968 NATO Software Engineering Conference. More recently, Douglas Crockford, creator of JSON (today’s most widely used data interchange format), has likened code reuse to the Holy Grail of software development.
Code reuse does have disadvantages. Installing third-party components (or package dependencies) can potentially introduce security vulnerabilities, the topic of a previous blog post. On occasion, code reuse can also result in broken builds, the web services equivalent of a power outage. Moreover, as Sandy Clark, a researcher at Apple and the University of Pennsylvania, points out: the more a given software project relies on third-party code packages, “the smaller the amount of study required by an attacker.” To gain a better understanding of how practitioners think about the risk-reward tradeoffs inherent in open source code reuse, IQT Labs recently surveyed 150 software engineers, data scientists, and web developers. This post highlights initial findings we hope can help security teams, developer experience researchers, and code security companies.
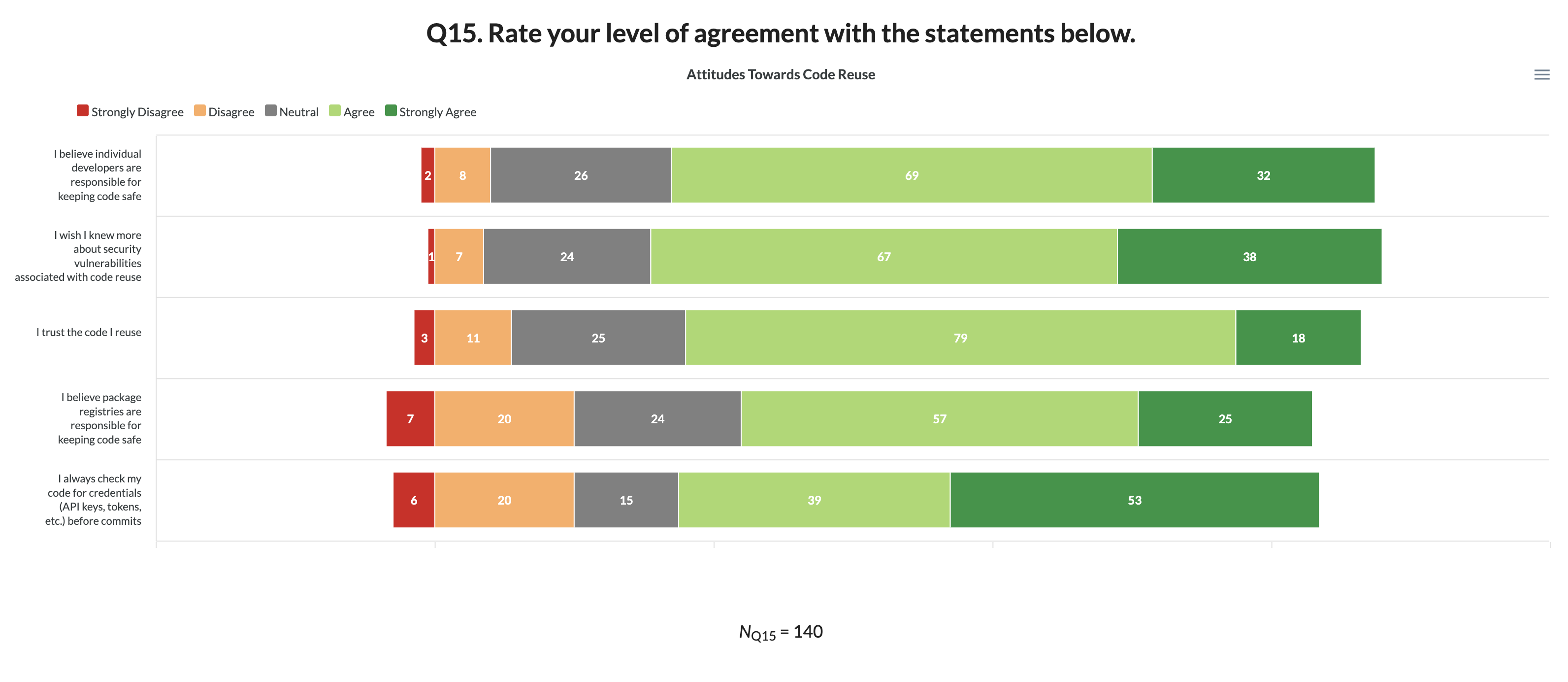
The results highlight major security knowledge gaps among coders, including challenges evaluating third-party packages using different information sources. Some of our more noteworthy findings include:
- A full 70% of survey takers agreed with the statement “I wish I knew more about security vulnerabilities associated with code reuse.” This finding underscores the importance of organizational support, particularly for coders with less than 10 years of experience, a topic we analyze further below.
- When asked who is responsible for keeping code safe, more than half (77/150) of respondents indicated security is a responsibility individual developers share with package registries. However, the assumption that package registries are devoting sufficient resources to software supply chain integrity is fundamentally at odds with developers’ real-world risk exposures to typosquatting and package hijacking.
- 25% of participants admitted they “do not engage in pre-install code vetting.”
You can explore the underlying data, along with a series of accompanying visualizations, here. Along with quantitative metrics on coding experience, professional identity, and tooling preferences, we also gathered qualitative feedback. Several survey participants echoed this sentiment about security hygiene:
I just did the survey, it was pretty interesting! It felt like going to the dentist – in that I realized there’s a bunch of best practice things I should be doing but am not…”
Survey Design
With more than 1.6 million Node.js packages and over 300,000 Python packages circulating on npm and PyPI, respectively, a lack of reliable user data is hindering productive discussion about the risk-reward tradeoffs associated with code reuse. As a result, we decided that developing a survey would be a useful step in learning more about the extent to which practitioners take calculated risks within package-based ecosystems like PyPI.
To guide our efforts, we reviewed a handful of existing developer surveys, three of which appear in Fig. 1.

Figure 1: Annual Developer Surveys Stack Overflow 2020 Developer Survey, The State of JS 2020, Jetbrains The State of Developer Ecosystem 2020
Although these surveys attract significant media attention, they tend to de-emphasize security and instead focus on pay scales, working conditions, tooling, and sentiment towards emerging technologies.
By contrast, we built a multi-part, 18 item questionnaire in SurveyMonkey, including one screening question (how often do you use the following package managers?), a manipulation check, and 10 security-related questions focused on code reuse. We designed the survey as an online convenience sample to enable us to compare results to existing datasets, and importantly, we did not collect any personally identifiable information.
Our original survey instrument is available here, with all questions grouped into the following categories:
- practitioner profiles (experience level, organizational context, and overall security posture);
- self-reported attitudes and behavioral predispositions (i.e., frequency/intensity of code reuse, as well as code evaluation behaviors and preferences, ranked using a five-point Likert scale).
IQT Labs recruited survey participants using a mix of email, Twitter, LinkedIn, and referrals from Data Science DC, Anaconda, Inc., and The Linux Foundation.
Ultimately, we collected 150 responses, which we summarize descriptively below and visually here.
Practitioner Profiles
Polyglot programming (the practice of coding in more than one programming language) is becoming increasingly widespread, and our data reflect this trend. Overall, our 150 survey takers use an average of 2.6 programming languages, shown in Fig. 2, including several of the most popular according to the latest RedMonk data as of 1Q21.

Figure 2: Main programming languages participants use
Consistent with these language usage data, the most frequently used package managers were pip (used on average once a week by 91% of respondents), followed by conda and npm (used on average once a month by over half the coders we surveyed). Roughly one-third of our sample also reported using Maven, yarn, and CRAN (which have fewer packages in total and more specialized security tools), as part of their package manager workflows.
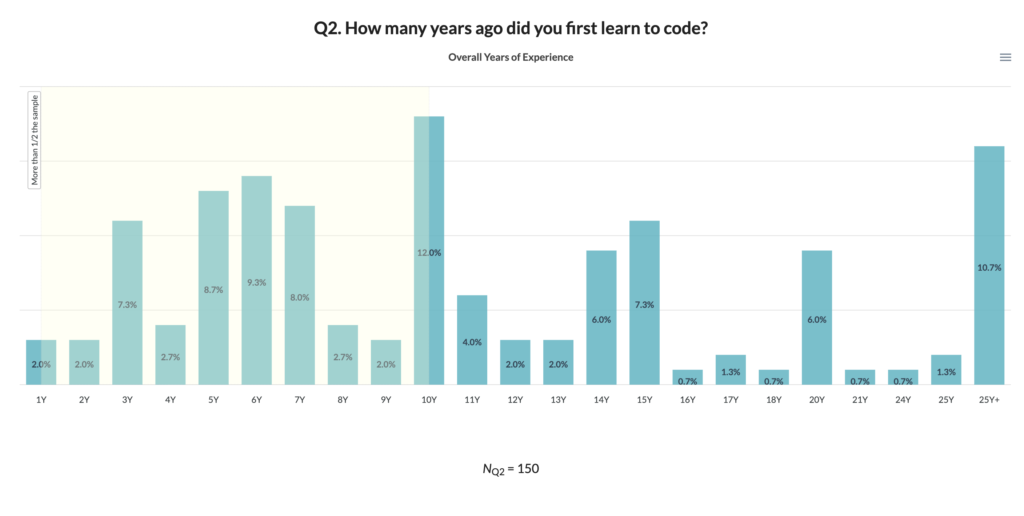
Figure 3: Years since starting to code (incl. school)
In terms of experience, the population we surveyed has been coding for an average of 7.8 years professionally (excluding school) and 11.5 years overall. This pattern, shown in Fig. 3, is in line with our comparator dataset from Stack Overflow, which found “approximately 40% [of programmers] learned to code less than 10 years ago.”
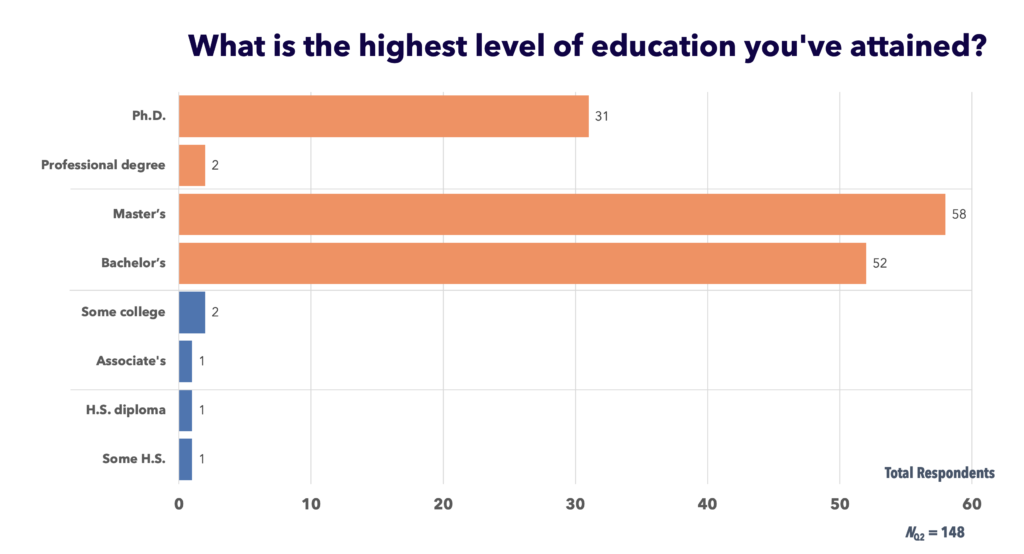
Figure 4: Participants’ educational attainment, ranging from ninth grade to doctoral study
The educational background data we collected was generally consistent with existing surveys. In our case, 143 survey participants (or 95%) reported bachelor’s degree-level of education or higher, compared to 75% of Stack Overflow’s 2020 survey of 65,000 developers. Our results, shown in Fig. 4, reflect a higher overall level of education in part because our convenience sample included outreach to graduate school classmates. A more robust future study calls for added recruitment of practitioners who learned to code outside of formal instructional settings.
In addition to building this general educational profile, we also asked survey takers about their professional identities. Our 150 respondents selected an average of 1.7 job titles and unsurprisingly, software developer/engineer and data scientist/ML researcher were the most common titles (44% and 35%, respectively). Another 20% identified as a student or educator, along with manager (16%) and front end developer/visualization engineer (12%), followed by a series of more specialized roles.
Self-Reported Attitudes and Behaviors
Overall, participants in the IQT Labs survey reported a relatively poor security posture.
42% selected the response “I consider myself a security novice,” a cohort who also reported uneasiness evaluating a new software library for security risks. Only 21 survey participants (or 14% of the total) reported membership in a security forum, and roughly half of those were security engineers/penetration testers.
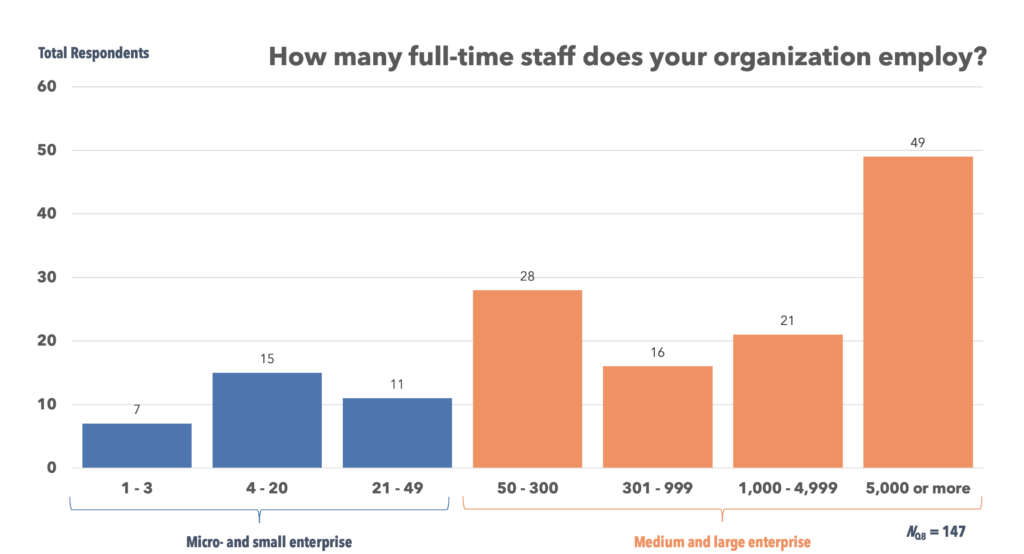
Figure 5: Organization size, grouped into two categories based on the OECD’s micro, small, medium, and large enterprise definitions*
Along with individual involvement in security, organizational context appears to be an important factor. Of the 113 survey takers working at a medium to large enterprise (entities with 50 or more staff, highlighted in red above), 66% identified two or more organizational security gaps: e.g., lack of training, specific IT policies, and/or dedicated code review resources. It is apparent public and private sector IT leaders at organizations of all sizes need to refocus on these areas, and we invite you to dig into accompanying visualizations here.
More than half of all respondents indicated security is a responsibility that individual coders share with package registries. Another 29% expressed the view that coders, more than registries, are primarily responsible for keeping their code safe. While it is difficult to generalize from these sentiments, at a minimum, our data suggest the registries may need to focus more on educating users on pre-install security scan tools and risk mitigation techniques.
Since secure code reuse involves a series of choices about which third-party software components to install, we asked various questions about what information sources and real-world evaluative criteria practitioners use.
Figure 6: Humorous Twitter post from Lea Verou of the MIT Computer Science & Artificial Intelligence Lab, which circulated widely last autumn
Our results suggest relatively casual attitudes towards code reuse security overall, although total years of experience seems to have a moderating influence on self-reported code vetting behaviors. Specifically, we found seasoned programmers with more than 10 years of overall experience (cf. Fig. 3 above) using a slightly different mix of information sources to research software packages, compared to early and mid-career developers. This is consistent both with academic security research on 7.5-year-old dormant vulnerabilities and with code practitioner intuitions (Fig. 6) about how long it takes to shed “bad habits” related to code reuse, another area ripe for follow-on research.
The top three sources of information for vetting packages were: Google (used by 92% of the sample), as well as Stack Overflow, and trusted peers, particularly among coders who have under a decade of experience. In contrast to those who Googled which packages to use, those who reported using package manager search tools (e.g., the PyPI user interface) had a decade or more of programming experience (13.5 years of coding overall, and 9.3 years coding professionally, with little variation across languages). Related interactive visualizations appear here.
Along with information sources, we also examined what vulnerability types and evaluative criteria practitioners deem important. When asked about their top concerns in the context of third-party package installation, survey-takers overwhelmingly selected generic risk factors (malware, credential theft, and undisclosed dependencies). Only 11% of the 150 selected “None.”
More specific vulnerabilities seemed to worry fewer respondents. Thus, package hijacking, defined as “malicious takeover of maintainer accounts” impacting one’s code appeared to be the second least important risk relative to typosquatting (i.e. “malicious code within a package that has a similar name to the package you plan to install”). However, the difference between hijacking and typosquatting concerns was slim: 48% vs. 46%, respectively, which on a survey of this size is negligible.
Finally, in terms of criteria “use[d] to determine if a software package is safe to install,” survey participants appeared to rely heavily on generic and potentially uninformative indicators. For over 80% of the sample, “package appears popular/widely trusted” was a consideration, along with “maintainer activity seems recent” (61%).
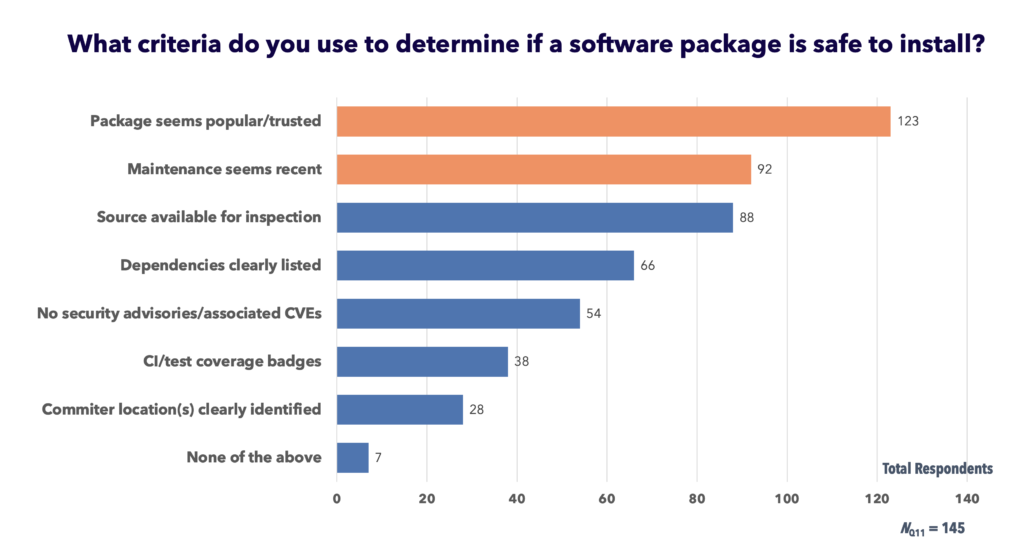
Figure 7. Self-reported decision criteria developers use to evaluate the safety of a given software package
As Fig. 7 above shows, very few (approximately one-fifth) of the coders who took the survey reported considering whether “[c]ommiter(s) [were] clearly identified by location (e.g., jsmith in Cambridge, UK),” vs. Cambridge, Massachusetts).”
IQT Labs recently sought to address this type of geographic comparison use-case with our GitGeo tool. In fact, since just under half of survey-takers said they lack adequate tools to perform pre-install security checks, the generalized lack of awareness that code provenance matters is particularly actionable for us. We see an opportunity to highlight the complex interplay between committer locations, institutional affiliations, and related reuse risks, to the extent these data are available, to help engineers and data scientists make better-informed code reuse choices in the future.
The Road Ahead
In a 2019 paper, a group of academic security researchers noted: “the same aspects that make [package-based software ecosystems like npm and PyPI] popular—ease of publishing code and importing external code—also create novel security issues, which have so far seen little study.” The Code Reuse Survey is IQT Labs’ effort to encourage further applied research in this important domain.
In addition to presenting results in greater depth to colleagues, customers, and other interested stakeholders, we invite you to explore interactive visualizations of our results here and take the survey yourself here. Please email the lead author at gsieniawski@iqt.org if you have any questions.
Acknowledgements
Thank you to Dan Geer, Matt Kemph, Mike Chadwick, Andrea Brennen, Vishal Sandesara, Carrie Sessine, Christyn Zehnder, Joely Friedman, Mark Huson, Joanna Johnson, George Lewis, Tommy Jones, Brian Norville, Samantha Wright, Josh Bailey, Luke Berndt, Ravi Pappu, Jeremy Joseph, Zach Lyman, Bob Gleichauf, and Pete Tague for their support.
Thanks also to David A. Wheeler of the Linux Foundation and Kevin Goldsmith of Anaconda, Inc. for promoting the survey to their networks on Twitter.
External reviewers at Harvard Business School, the University of Virginia Department of Psychology, and the Mendoza College of Business at the University of Notre Dame also provided feedback. While we are privileged to have access to so many sources of feedback and dissemination, this remains our work and any remaining errors are ours alone.
Related Content
To learn more about related IQT Labs research, read the following articles:
“Toward Secure Code Reuse,” IQT Blog, Feb. 2021
“Counting Broken Links,” USENIX ;login:, Dec. 2020
“Who Will Pay the Piper for Open Source Software Maintenance?” USENIX ;login:, Jun. 2020
Related Open Source Software
To learn more about IQT Labs’ software development projects in this area, visit the following GitHub repositories:
pypi-scan: a command-line tool that checks for misspelling attacks in Python packages
GitGeo: a command-line tool that maps the self-reported locations of committers on a GitHub repo
» Also, please watch the IQT Labs GitHub repo to keep track of our applied research and prototyping efforts.
Related Portfolio Companies
In-Q-Tel invests in a wide variety of technology domains. The following investments relate to the focus of this article:
Coder moves developer workspaces into the cloud to centralize their creation and management, providing a controlled, consistent environment for software development.
GitLab supports the entire software development lifecycle, including source code management, continuous integration and delivery, and automated security, code quality, and vulnerability management.
Sonatype allows developers to use open source software more safely and securely by offering management and assessment tools that can be integrated into existing software development workflows.
Veracode enables identification and management of security risk across an entire application portfolio through a suite of application security testing tools, including a consolidated view of application status.
» Do you have a product or technology that can contribute to national security capabilities? Visit https://www.iqt.org/company-submission/ to start the conversation.