


Part 1: The Challenge
How do you know if the content you’re watching on YouTube is real? Did the president really just say that? Could it have been a gaffe or did the video get manipulated? Did a young, deflated Silvester Stallone really star in Home Alone? Ok, fair enough, for sure not that last one. But these so-called deepfake videos highlight their increasing prevalence and possibilities for digital deception, which means there’s even more reason to be skeptical of online content. The increasing ease with which deep learning tools can be used by non-experts to make deepfakes means that the problem is not going away anytime soon. So, what are we to do?
In this two-part series, we describe a state-of-the-art dataset associated with the DeepFake Detection Challenge released at the end of 2019. This post focuses on the dataset itself, how it was built, and details of the challenge. In the second part, we discuss how we built our own multimodal submission, the results of the challenge, and an overview of the top performing models. We also highlight our insights into the problem of deepfake detection that led to a follow-up project, FakeFinder, where we have built an extensible, scalable, and adaptable detection platform.
Before diving into the details of the problem, let’s start with a quick review of the technology powering the deepfake boom. Over the last half-decade or so, machine learning methods have evolved along with ever-more powerful (and accessible) compute power to produce incredibly high-fidelity representations of data distributions. Techniques employing generative adversarial networks (GAN) can and have been used as an effective ‘enhance’ button for imagery or to build datasets for healthcare and finance where protecting privacy is paramount. But these methods have gained notoriety for producing particularly impressive synthetic imagery and audio, capable of fooling some of the most astute eyes and ears. Furthermore, its presence on social media platforms specifically present a ripe opportunity for agents out to fool us.

Since social media companies are continuously inundated with new content, Facebook saw an opportunity to approach the deepfake detection problem by constructing their own dataset. At NeurIPS 2019, Facebook launched the DeepFake Detection Challenge (DFDC), inviting the public to participate by submitting their own solutions for identifying deepfake videos. Running this competition in the open source, Facebook effectively ensured transparent verification and comparison of methods on a standardized dataset.
Deep Fake Detection Dataset
The DFDC dataset comprises a whopping 25 TB of raw footage, making it the largest publicly available deepfake dataset. To build it they recruited nearly 3,500 people to be on-screen, which after applying deepfake tech to the real videos, resulted in 48k videos spanning 38 days’ worth of footage. Since most deepfakes found online are sourced from particular conditions (think press conferences for political leaders, Steve Buscemi TV acceptance speeches, or Nick Cage as all characters in a movie scene), Facebook put their actors in more natural settings, without professional lighting installations or make-up. See the image below for some examples.

Generation methods
There are numerous methods out there for producing deepfake videos. Since Facebook started by filming real actors and actresses, the DFDC dataset used face-swapping, where the face of someone in a video is replaced by another. Hence, the videos which have had actors’ faces swapped are labelled as the deepfakes in the data. The organizers chose to use five popular deepfake methods at the time of dataset creation, and the distribution in the dataset of fake videos generated with each reflected their representation online. The swapping methods in order of dataset representation are:
- DeepFake AutoEncoder (DFAE)
- Morphable Mask (MM)
- Neural Talking Heads (NTH)
- FaceSwap GAN (FSGAN)
- Modified StyleGAN
The first two on the list constitute the less heavy-duty swapping techniques. The DFAE method uses a modified autoencoding structure with two separately trained decoders (one for each identity in the swap) and an extra shared layer in the encoder which improves lighting and pose transfer. While producing some of the best deepfake results, DFAE did have trouble swapping when eyeglasses were present or with extreme poses. With the MM technique, facial landmarks facilitate face swapping along with morphing and blending techniques. This resulted in visibly evident manipulation from facial discontinuities and failure in mask-fitting for landmarks, though this method was capable of fooling single-frame detectors.
The remaining three methods implement GAN frameworks. The NTH model represents a framework for meta-learning of GAN with few examples, i.e., few-shot adversarial learning. This technique is well-known for creating so-called ‘living portraits’, though it did not produce good results in low-lighting conditions. The FSGAN method trains several generator models for identity swapping via segmentation, reenactment, and seamless blending in a manner that is face agnostic. This made it the strongest technique for the most extreme angles and poses. And finally, when using StyleGAN, facial descriptors were projected onto the latent sampling “style” space of the StyleGAN model itself to conduct the facial swapping. However, the organizers note that this method produced the worst manipulated videos in the set, in particular generating random gazes and issues with matching illumination in scenes.
Once a deepfake video was generated using one of the above methods, a random selection was put through a refinement processing, visually enhancing the perceptual quality of those final videos. We note that in addition to the imagery manipulation, the DFDC dataset also includes audio swapping between the real and deepfake videos. Specifically, the text-to-speech (TTS) skins voice conversion was implemented to generate synthetic voice from source transcripts. These manipulations were not considered ‘deepfakes’ for the competition. They were included, however, in the hopes that they may serve for further research.
Scoring and rules
Of course, for the purposes of the challenge, the details regarding these models and manipulations were hidden until after the competition closed and the final scores released. This also includes additional augmentations (blurring, flipping, contrast adjustment, etc.) and implanted distractors (random text, shapes, overlayed images) to 70% and 30% of videos, respectively.
Further complicating things was that the public, labelled set is highly imbalanced. Although each fake video is associated to one real video from which it was sourced, the ratio of fakes to real was nearly five to one (104k fake, 24k real). Thus, to train classification models with these videos, we had to define a balanced subset of data. To create our set, we randomly selected a single fake video to its associated real counterpart. This ultimately provided us a training set of 50k videos. These are of course details of how the IQT Labs team prepared for training. Other participants in the challenge likely chose different data splits.
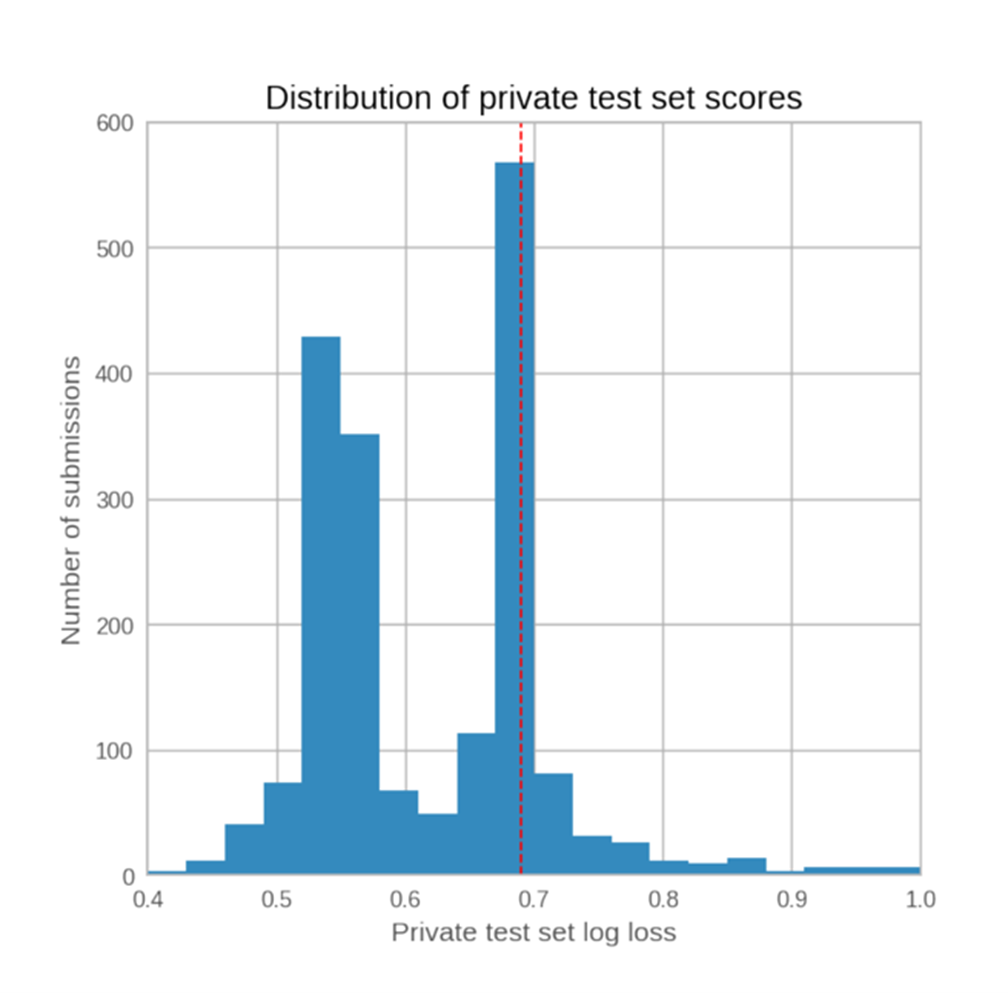
Ultimately, however, results from deepfake detection on the private, hidden test set provided the scoring metrics for the competition. Specifically, models were ranked via the logarithm of their evaluated loss value. As shown in the figure above, the full, competition wide-results give us an idea of how deepfake detectors might fare on a more real-world distribution of video content. Over 2,000 teams participated in the competition, each allowed to provide two final submissions. Perhaps emphasizing the difficulty of the task, only about 40% of the submissions scored better than chance detection (i.e., 0.5 average probability fake/real detection). And even though the private set included subjects that were not found in the public dataset, the challenge organizers found a fair correlation between scoring well on the private set and scoring well on the public one, which ultimately suggests that Facebook’s DFDC at least provides a significant contribution towards generalizing deepfake detection.
While the DFDC and its dataset do not capture all deepfake capabilities nor all potential use cases, they do illustrate the difficulties scaling the problem of identifying deepfake videos. In our next blog post we will detail the methods IQT Labs implemented and those of the top five submissions.