


Introduction
Computer vision has improved to the point that it is trivial to localize a face from a clear photo. But what happens when you have grainy video, with audio or image data cutting in and out?
When making predictions in machine learning, we usually use a single modality of data. We talk about computer vision and natural language processing as separate fields, but this isn’t how humans learn. We identify things by using all available senses.
In ML parlance, this task is often called sensor fusion or multimodal learning. The phrase sensor fusion has caught on because this technique is commonly seen in fields with actual physical sensors providing inputs, like self-driving cars. A self-driving car might have camera and LIDAR input (light detection and ranging or laser imaging, detection, and ranging; LIDAR sometimes is called 3-D laser scanning). The visual camera can detect what LIDAR cannot, and vice versa. The combination is helpful, since they (in theory) could compensate for each other’s weaknesses.
The Fusing Without Confusing (FWoC) ML pipeline enables sensor fusion with an end-to-end ML pipeline for experimenting with different fusion techniques. FWoC contains support for text, video, biometrics, and images, and is based on a flexible and extensible architecture that can expand into new areas in the future. In this study, we focused on video and audio.
Currently, facial image recognition is a common approach to person identification, but what if the face in question is blurry or otherwise corrupted? A person has other identifying characteristics than their face, such as speech, gait, or DNA. Multimodal identity intelligence was the first problem we investigated using the FWoC system. We started with combining speech and face data to identify a person from a corpus of different identities.
We investigated advantages and trade-offs in using multimodal systems for identity intelligence, both in supervised and few-shot models. This effort builds on previous multi-modality identity intelligence research within IQT Labs, in deepfake detection, where we first examined model performance as separate modalities were combined. With FWoC, , we benchmarked several multimodal (audio, video, single frame) fused models on person re-identification and few-shot identification. We have created an extensible machine learning pipeline called Fusing Without Confusing (FWoC) to enable this work.
As part of a feasibility study of determining approaches and technical requirements and gathering preliminary results, we trained speech and vision models on the multimodal identity dataset VoxCeleb2*. VoxCeleb2 is a dataset of short clips of human speech extracted from interviews on YouTube, with more than 1 million utterances and 6,000+ different speakers of different ethnicities, ages, accents, and manners of speaking. The size of this dataset is 333 GB. This dataset is typically used to generate models that can recognize unique speakers.
To explore data fusion with VoxCeleb2, we implemented multiple deep learning models in PyTorch. These models embedded the audio and/or video streams into fixed length vector representations called embeddings. An embeddings model takes in a data (for example, an image) and creates a vector that captures the abstract meaning of the data. The phrase “abstract meaning” means that data that is similar should create similar vectors. For example, a face embedding of two separate images of a person will create very similar vectors (close together) if they belong to the same person. Prediction of the class or label of data example without ever being trained on that label at all is called Zero-Shot Learning.
Typically, zero-shot predictions are made with embedding models alone (no trained classifier is involved). Person re-identification is an example of zero-shot learning. The system might not have any examples of a person and it could decide that the two embedding vectors refer to the same person if they are very similar (close together in space).
Modality Fusion
Modality fusion is the transformation of data from multiple single-modality representations to a compact multimodal representation. The process generally involves taking the corresponding embeddings of different modalities and combining them using either simple concatenation or other statistical techniques (Figure 1). We experimented with two approaches to fusing the embeddings produced by different models into a single model.
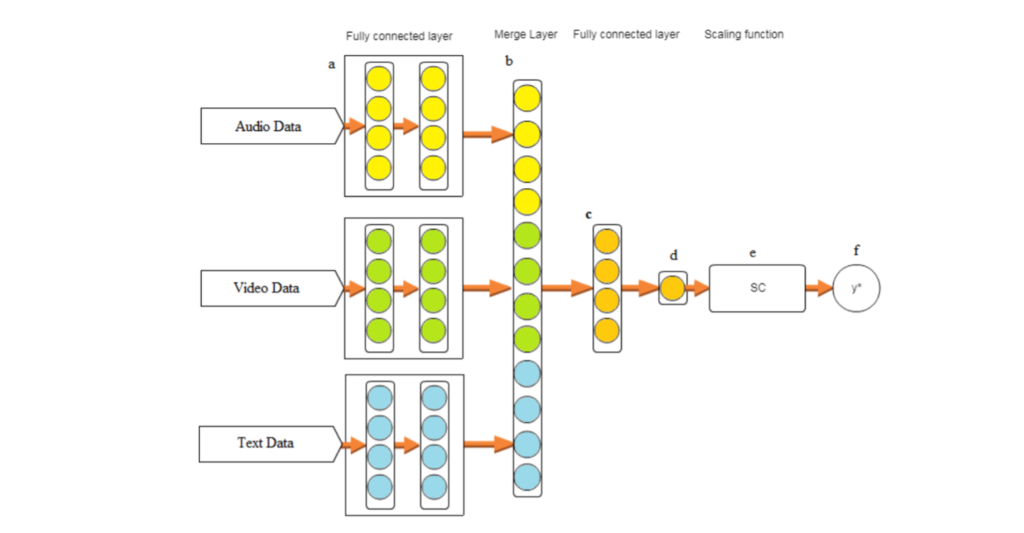
Linear Fusion
The first approach is a simple linear fusion layer that takes in the output from each model, concatenates them into a single vector, and multiplies this vector by a matrix to produce the final embedding.
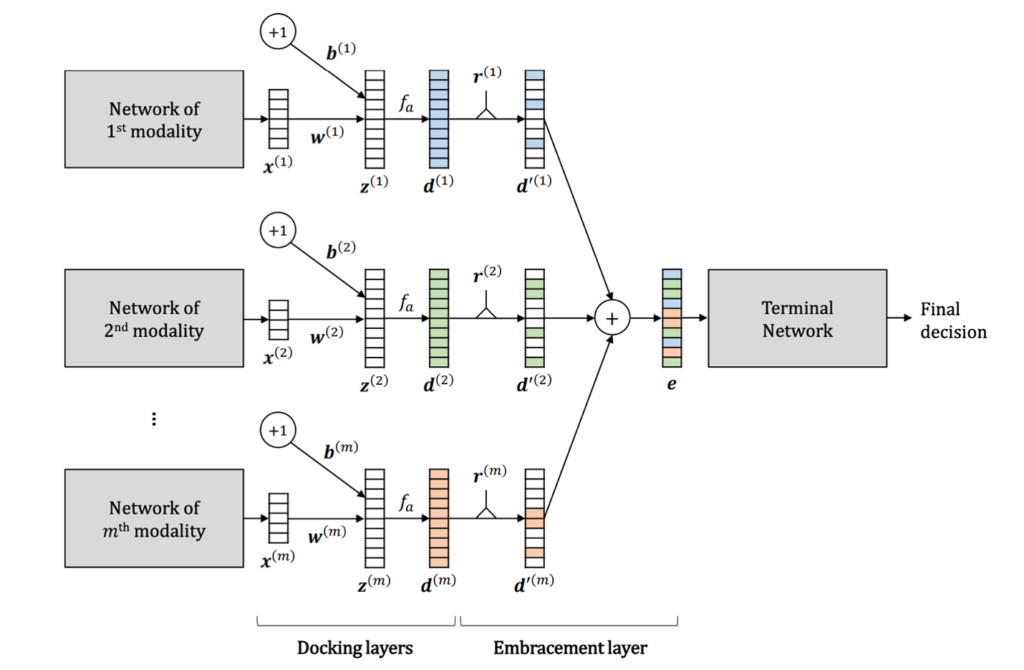
EmbraceNet
The second, more complex and sophisticated approach is based upon EmbraceNet (Figure 3). First, each model’s output is linearly transformed so that all outputs have the same dimension. Then for each coordinate in the final embedding, the value is selected at random from the set of corresponding coordinates in the models’ output vectors. This stochastic interleaving procedure forces each model to learn representations that are redundant and coordinated. We also trained embedding models composed of each of the above-described models in isolation with a linear fusion layer applied to their output.
The dimensionality of the final embedding for each single modality embedding model and both fusion approaches is 256, across all experiments.
Training Algorithms
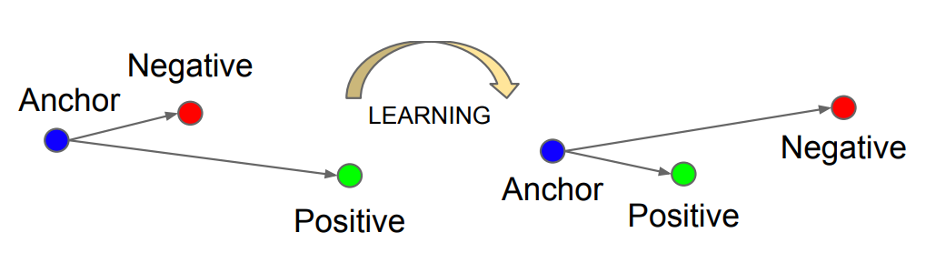
We explored the use of two different loss functions for training our two embedding approaches – – cross– entropy loss and triplet loss.
Cross-entropy loss, or log loss, measures the performance of a classification model and its output is a probability value between 0 and 1. ForTriplet loss a reference input (called anchor) is compared to a matching input (called positive) and a non-matching input (called negative). The distance from the anchor to the positive is minimized, and the distance from the anchor to the negative input is maximized as seen in Figure 4. This is useful in the scenarios of Zero –Shot or Few– Shot Learning where the trained model has never seen a sample before or has been trained with very few samples. In both cases, the models were trained end to end, simultaneously optimizing parameters of all single-modality models as well as fusers, using the Adam optimizer. The entire dev split of (VoxCeleb2) VC2 was used for training, with an 80-20 train-validation split. Models were trained for 20 epochs, and the checkpoint with the highest accuracy on the validation set (defined below for each loss function) was retained. Loss functions, training routines, and checkpointing were implemented using PyTorch-Lightning, a high-level library for deep learning in PyTorch. This library was used because it provided a better scaling and interaction capabilities for Ddeep lLearning models. It also provides a host of housekeeping activities like checkpointing, integration with logging frameworks and automated training runs.
Evaluation Metrics
For each model that we trained, we evaluate its performance with respect to four metrics that emulate different downstream tasks in identity intelligence that zero-shot embedding models are commonly used for. Figure 5 illustrates the common metrics that were evaluated.
We evaluate these metrics using the entire test set, which contains 118 identities, 4,911 videos, and 36,237 total utterances. Importantly, because there is no overlap in identities between the train and test splits, performance on the test split measures how well the embedding model has learned the inductive bias that videos of different identities should be mapped to distinct points in embedding space and videos of the same identity mapped to nearby points, as opposed to just memorizing identities in the training set.
Findings
Due to extensive compute issues encountered during training of these fused models with video data, the results that we have reported below are from models that have been trained for less than the optimal 50 epochs. On average, Log loss training for models was taking around a 25 hours per epoch and Triplet Loss training was taking 5 days for a single epoch. Hence, the Log Loss models have been trained for up to 20 epochs and Triplet Loss models have been trained for up to 2 epochs. Despite these limitations, we observed some model training convergence and interesting indications that are detailed below.
Verification
Even though we report other supporting metrices, we used identity verification as the primary metric for evaluating fused models. AUC – ROC curve is a performance measurement for the classification problems at various threshold settings. ROC is a probability curve and AUC represents the degree or measure of separability. An excellent model has AUC near 1 which means it has a good measure of separability. A poor model has an AUC near 0 which means it has the worst measure of separability. When AUC is 0.5, it means the model has no class separation capacity whatsoever.
We benchmarked VoxCeleb2 using FaceNet with a Logistic Regression classifier and obtained an AUC/ROC of 0.98. FaceNet is a face recognition model that is state-of-the-art on some public benchmarks. The result is not surprising as FaceNet gets AUC around 0.98+ or even 0.99+ on most biometrics datasets, we have not seen it used on VoxCeleb2. As an input it only takes in a normalized face. It does not use any video or audio. The faces inputted into FaceNet were extracted from the video using another model called MT-CNN. We used FaceNet as a control. It does not use the same pipeline as the rest of the models, nor does it use fusion. This metric proved helpful in understanding the results of the model fusion, to understand how close our results were to state-of-the-art results with the fused models we experimented with. In fact, as you see from the results, fused models do not approach the state-of-the-art of traditional face recognition.
As can be seen from Figure 6, triplet loss training with linearly fused models demonstrates the best model convergence. Using EmbraceNet fusion seems to slow the convergence of the trained model, hence the technique does not seem to be particularly useful for modality fusion when models that are being fused have dissimilar features.
Linearly fusing multiple modalities with Log loss training does not learn to perform beyond random chance.

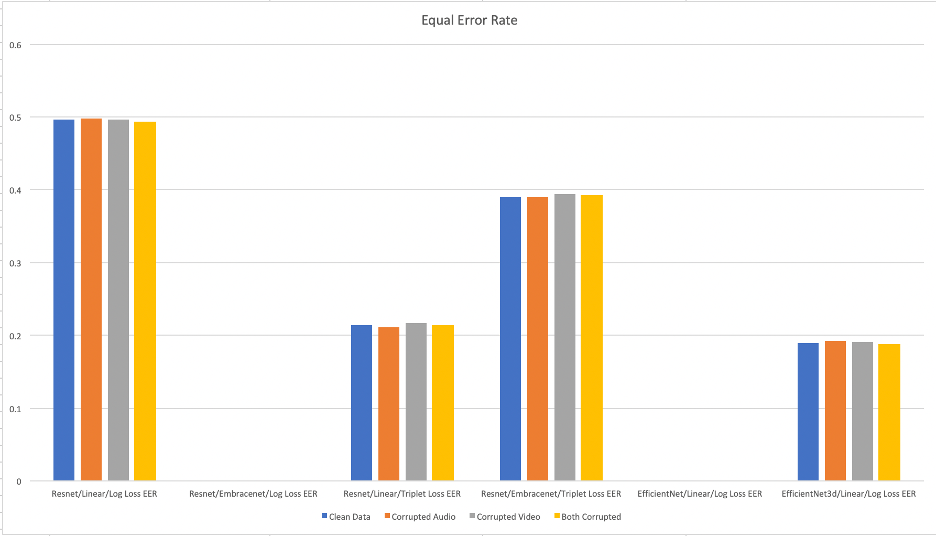
Equal error rate (EER) is a common biometric metric used to predetermine the threshold values for its false acceptance rate and false rejection rate. When the rates are equal, the common value is referred to as the equal error rate. The value indicates that the proportion of false acceptances is equal to the proportion of false rejections. The lower the equal error rate value, the higher the accuracy of the biometric system. As can be seen from Figure 8, even though some of Linearly fused and log loss trained models have a very low EER, given their AUC of around 0.5, these models are not very useful for the purpose of identity verification.
Triplet Loss trained models provide a much better ability to do classification based on both metrics.
Clustering
Clustering is particularly useful when identifying unknown identities in dataset. We provide two metrics to measure the ability of the trained to model to cluster unknown identities in the test dataset.
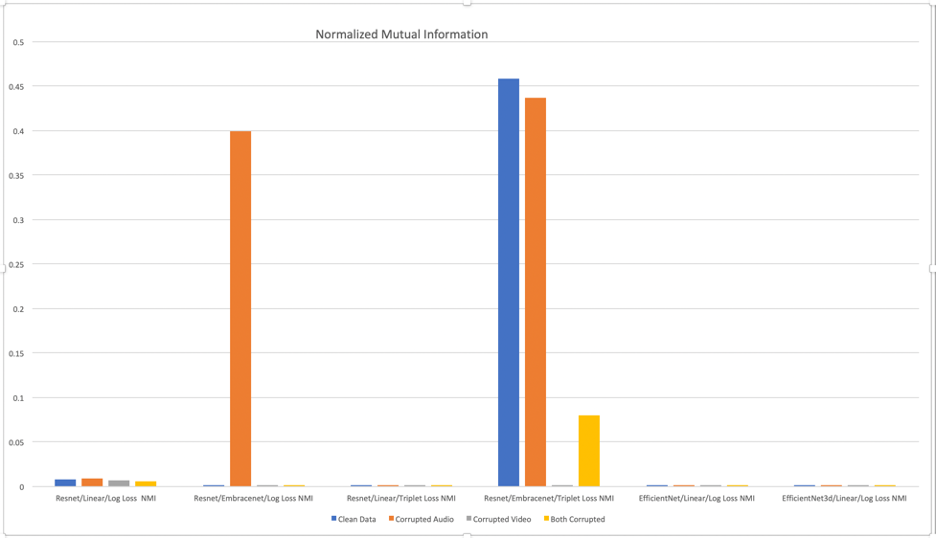
Normalized Mutual Information (NMI) is a measure used to evaluate the quality of clustering. NMI is a normalization of the Mutual Information (MI) score to scale the results between 0 (which indicates no mutual information) and 1 (perfect correlation)
As can be seen in Figure 8, EmbraceNet seems to improve the quality of clustering for both Log Loss and Triplet Loss.
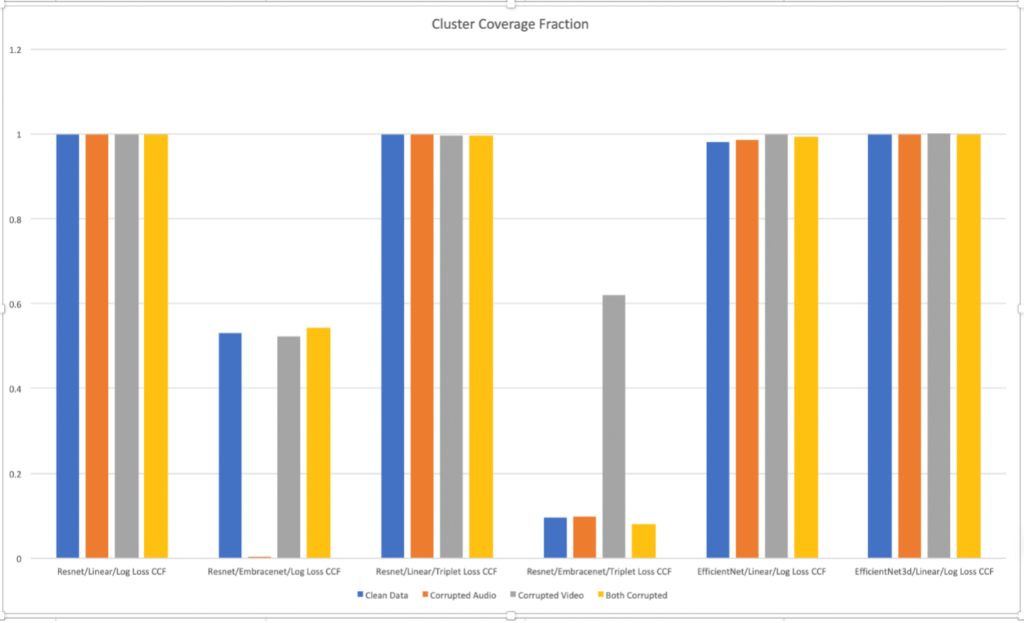
Cluster coverage fraction is the percentage of embeddings assigned to a cluster and not outliers. As can be seen from Figure 9, all of models indicate good coverage except for those trained using EmbraceNet.
Information Retrieval
This metric measures the ability of the trained model to search for similar embeddings. Average Precision (AP) is finding the area under the precision recall curve. mAP (mean average precision) is the average of AP.
In this metric as well, triplet loss training and linear fusion stands out over other methods as shown in Figure 10. As can be seen in the case of Resnet/Linear and Resnet/EmbraceNet, this method of fusion seems to lower the overall metrics.
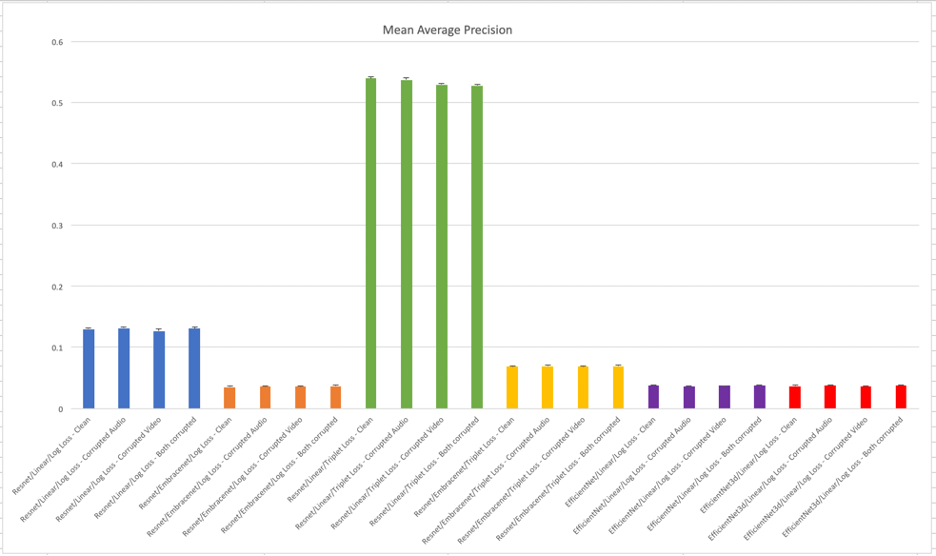
Identification
With this metric we are trying to measure how accurately the trained model can classify the identity of the person in a video. Accuracy is the fraction of the predictions that the model got right.
We see similar results with respect to triplet loss and degradation of model’s ability to accurately identify when using EmbraceNet, Though, in this case, the degradation is more pronounced in the case of triplet loss as seen in Figure 11.
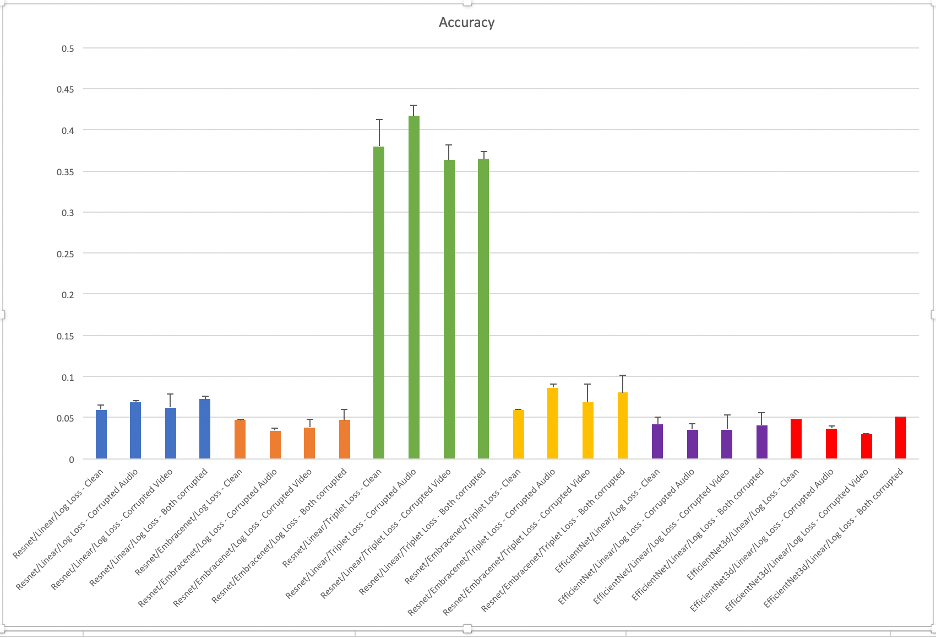
Conclusion
The primary finding from this work is that linearly fusing audio and video models and training using triplet loss works very well on a number of metrics. Even when compared to single modality benchmark for verification on FaceNet, a highly performant model, the triplet loss training for the fused audio and video model gave good convergence after a single epoch. Training triplet loss with videos is extremely compute intensive, hence it is interesting to see convergence after a few epochs.
We trained multiple fused models using EmbraceNet and naïve (Linear) fusion on this dataset. The training of these models is highly compute intensive and time consuming. For example, a single epoch of triplet loss takes 5 days to run on a high-end GPU AMI from Amazon. We believe this is due to the heavy amount of I/O bandwidth needed to train large neural network models on the large VoxCeleb2 dataset. As can been seen from the results discussed above, training using log loss does not seem to offer any value. The fused model (Linear or EmbraceNet) does not appear to learn anything. Even though, we were not able to train completely till 50 epochs due to compute and time issues, the training does not appear to converge. Triplet Loss on other hand shows a remarkable convergence even after a single epoch of training. Interestingly, EmbraceNet fusion technique seems to degrade model convergence for triplet loss. Overall it appears that linearly fused models with triplet loss training seem to perform best.
The performance is still well below state-of-the-art face recognition models like FaceNet. It is worth mentioning that FaceNet is also trained using triplet loss. We consider that triplet loss is a very good methodology for this biometrics problem in general. The difference that perhaps makes FaceNet performance so high is that it uses single normalized faces as inputs, while the other models use the full audio and video. Counterintuitively, giving too much data to a machine learning model may cause it to underperform, especially if it is not trained long enough (due to time and hardware constraints) as is the case with the other models in this paper.
Significant lessons were learned with respect to hardware infrastructure challenges (GPUS, memory, IOPS) involved in training fused audio and video models which are very large. The VC2 dataset presented its own set of issues with data cleanliness and presented significant obstacles during loading large batch sizes, that in turn slowed the training considerably. This .will inform future IQT Labs projects and serve as a foundation for additional external research in this field. Future work could include adding new datasets and modalities. Interesting areas include chemical property analysis for materials science or drug discovery. We could use the MoleculeNet dataset for this task. Chemical property prediction does not require huge datasets like VoxCeleb2, which would make experimentation faster. Additional models based on the current state-of-the-art could also be implemented, for example using the biometrics optimized FaceNet neural network instead of the object detection optimized ResNet neural network for the video processing within the model.