

The Geography of Open Source Data Science: Mapping Anaconda Code Contributors

In the 20th century, when analysts wanted to understand international patterns of technology diffusion, they looked to patent and academic citation data. Contemporary researchers still do. Today, however, there’s an additional data source on international technology trends to explore: open source software metadata. Platforms like GitLab, GitHub, and the Chinese equivalent Gitee have become global software development hubs where contributors create widely used software in public, leaving a trail of digital dust for others to follow. Consequently, collecting and analyzing publicly available open source software data may help analysts interested in science and technology intelligence and technology competition.
To demonstrate this potential, this post analyzes the locations of contributors to prominent open source data science software packages. We used an IQT Labs tool called GitGeo to build a dataset of the approximately 25,000 top contributors to Anaconda, a Python distribution that contains popular, widely used data science packages. We then investigate the self-reported locations of these contributors, analyze country-by-country trends and software development patterns, and perform an in-depth analysis of top Anaconda contributors based in Russia. A final section provides analytical details.
Our key findings include:
- Largely U.S. and European contributors: The top contributors largely come from the United States (37%) and western Europe (20%). Chinese-, Russian-, and Indian-based contributors each comprise less than 3% of total contributors.
- Something in the North Sea water?: Nordic countries have the highest per-capita rate of top contributors, perhaps due to recent tech investment in the region.
- Package communities are more like NATO, not the UN: The number of unique countries associated with a package range from one to 30. The average is 13.• If GitHub is the new résumé, is it also the new LinkedIn? Top Russia-based Anaconda contributors can–with high confidence–be linked to their real persona.
The Global Landscape of Open Source Data Science
To assess broad cross-country patterns of contributions to open source data science software packages, we analyzed the location of the top 100 contributors per package to the approximately 650 Python packages that comprise Anaconda. We applied GitGeo, an open source software intelligence tool started at IQT Labs, to the approximately 525 Anaconda packages for which we could find a GitHub link. Figure 1 resulted.
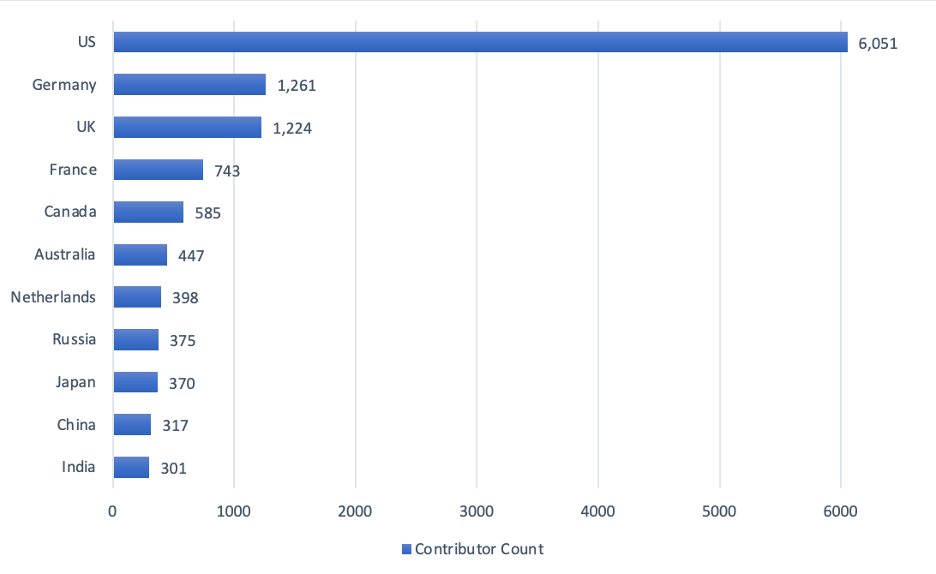
U.S.-, western Europe-, Canada-, and Australia-based software developers are the most prolific contributors to Anaconda packages. Russia-, China-, and India-based contributors number between 300 – 400 noticeably less. While there might or might not be a global “AI arms race,” it’s clear that U.S.-based Python data science package contributors–measured by raw commits to packages in Anaconda–have a noticeably higher count than other countries, potentially due to the historical roots of the software industry in the United States. Figure 2 visualizes this data on a world map.
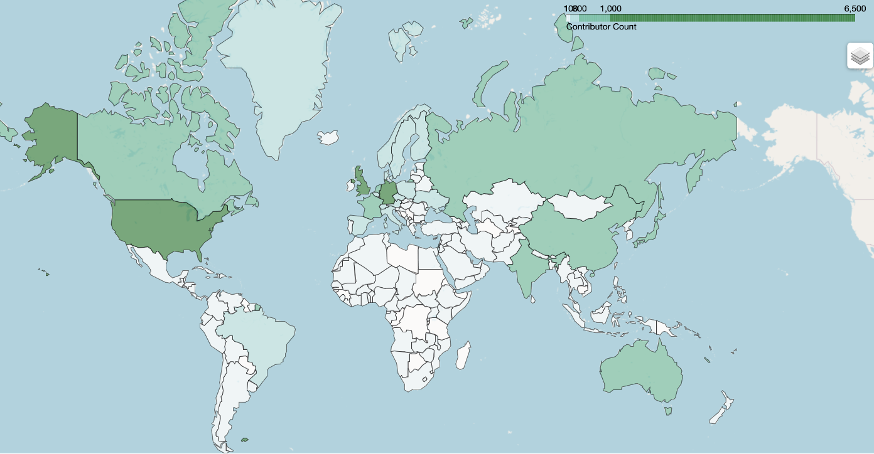
Python Packages Included in Anaconda
Additional investigation found that when focusing only on the top 5 contributors, the relative ranking remained similar, except that Finland-based developers noticeably jumped up in the index while China- and India-based developers counts dropped. Finally, an analysis using data only from September 2020 to September 2021 did find that the gap between the “West and the rest” had narrowed considerably. For instance, in the first analysis U.S.-based contributors outnumbered China-based contributors 19 to 1; using recent data only, the gap narrowed to 10 to 1.
Because country population size varies widely, we also analyzed contributor count per capita. See figure 3.
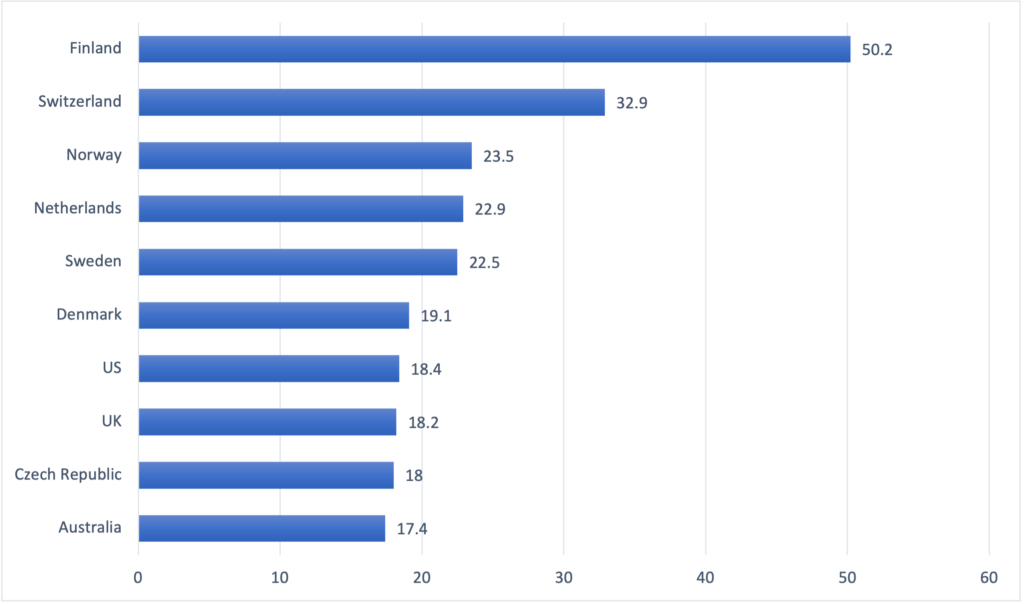
Nordic countries consistently have the highest per capita rates of top contributors to these Python open source data science packages. Why? We’re not sure, but one possibility worth further research has to do with national technological capabilities. Finally, when adjusting the raw contribution totals per capita, Russia (2.6 per 1M), China (.2), and India (.2) all dropped noticeably in the rankings per capita.
Patterns of Open Source Data Science Software Production
This open source software metadata can be mined for more than country-by-country insights. We also examined the number of unique countries represented within the top contributors to each package. See figure 4.
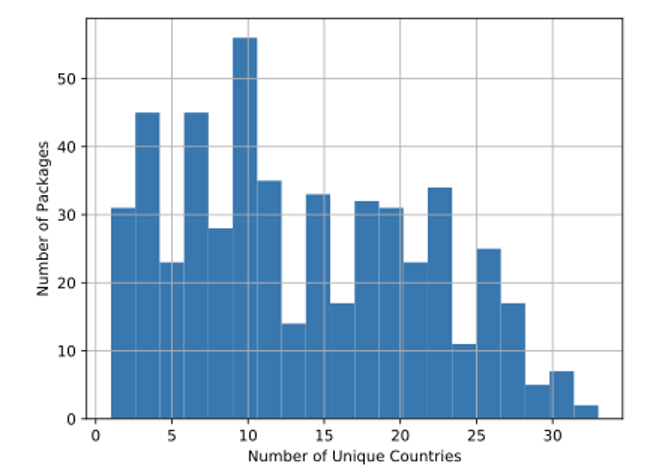
The average number of unique countries represented in the top 100 contributors for these packages is thirteen. In other words, these packages are certainly cross-national phenomena, but the developer countries tend to cluster, consistent with previous open source software research.
We also examined the time since the most recent code contribution (or “commit”) for these packages. See figure 5.
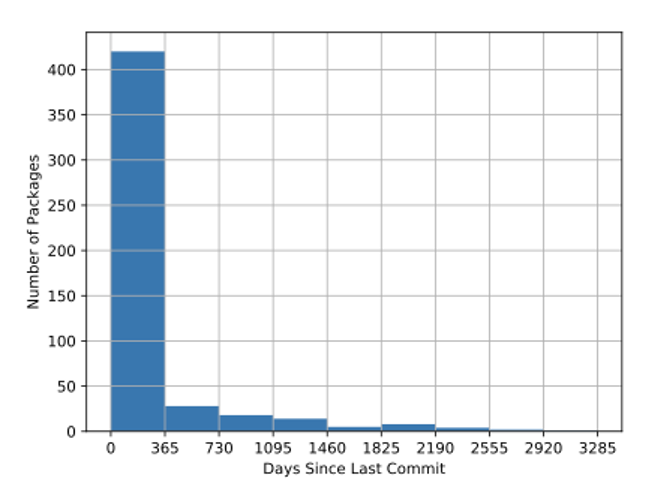
While the vast majority of packages have had updates within the past year, nearly 100 have not, suggesting that useful open source data science packages don’t always have active ongoing development.
We finally engaged in what may be termed OSSINT, or open source software intelligence. We filtered the data down to the top Russia-based contributors for these packages and discovered that these developers’ real-life details can–like many people–be linked with their online personas, which, in this case, are GitHub handles. For instance, these developers tend to work at large software companies (Intel, Apple, Databricks, Red Hat, Yandex), suggesting an increasingly close connection between business and the open source software community.
Anaconda Package Data
To create the data for the analyses above, we first scraped the Python 3.9 Linux Anaconda distribution for a dataset of 678 Python package names and associated hyperlinks. We then manually reviewed the links, performed web searches, and ultimately were able to create a list of 524 GitHub links. Some Python packages do not use GitHub or have no readily discoverable link to a source code management system. Then, we applied GitGeo to these GitHub links, building a dataset of (up to) the top 100 contributors for each package, or 24,638 contributors in total. While misleading GitHub profiles are widespread, roughly two-thirds of these contributors included location data in their profile, which enabled geographic analysis.
It’s worth noting that these packages represent only a fraction of the larger Python ecosystem, which has over 300,000 packages in its popular repository. Additionally, the analyzed packages do not represent all of data science, which encompasses many other language ecosystems.
Open Source Software Metadata as the Original Publicly Available Information
There’s a growing interest in open source intelligence, sometimes also referred to as publicly available information. Groups like Bellingcat have shown what internet data plus a group of internet-connected and capable analysts can do. Open source software metadata, however, has played second fiddle to social media data in this story. This blog post has tried to show why it might be time to focus more on open source software metadata. Open source software metadata concerns the software, the people, and the institutions that are helping to define the digital age. And unlike patents and academic citations, which deal largely with inventors citing each other, open source software metadata involves inventors and users interacting in the open. In short, it’s time to consider upgrading the importance of open source software metadata.
Thank you to Josh Bailey, LTC Tom Pike, Jackie Kazil, and members of the open source software neighborhood watch for helpful review.
To learn more about related projects, see:
- “GitGeo: Discover the Geography of Open Source Software,” IQT Labs Blog, April 2021.
- Dan Geer and George P. Sieniawski, “Who Will Pay the Piper for Open Source Software Maintenance? Can We Increase Reliability as We Increase Reliance?” USENIX ;login:, Summer 2020.
- deps2repos – Beta tool for seeing your code dependencies in their original context.