

The Machine Learning Utility Manifold for Satellite Imagery
Preface: The work summarized here stems from research conducted by Ryan Lewis, Jake Shermeyer, Daniel Hogan, Nick Weir, Dave Lindenbaum, Lee Cohn, and the author.
The utility of any dataset is dependent on a multitude of variables. Over the last few years CosmiQ Works has systematically worked to quantify the utility of satellite imagery datasets, a concept referred to as the Satellite Utility Manifold. The surface of the utility manifold has important tactical and strategic ramifications. For example one could compare the tradeoffs of sensor resolution, collection frequency, and cost (see Figure 1). By quantifying the utility surface and confidence intervals for a variety of axes, the CosmiQ Works team has sought to inform a number of important questions in the geospatial analytics domain, such as sensor quality, sensor resolution, dataset size, and resource requirements.
In the sections below, we discuss in further detail the motivation and potential impact of applied research focused on machine learning data requirements over multiple dimensions of import to the geospatial analytics community. See the full paper for further investigation into axes of interest.
1. Motivation
Data is the fundamental currency of machine learning, yet input data for machine learning projects is often treated as a nearly immutable resource. Most parties (such as academic researchers or technology startups) are not highly incentivized to spend significant effort studying the many nuances of datasets, and how those nuances inform and impact machine learning projects. On one end of the research/deployment spectrum, academic researchers are heavily incentivized to focus on novel algorithms even when added complexity may not bring an appreciable increase in performance [a b, c, d, e]. On the other end of the spectrum, corporations and government agencies are highly focused on deploying maximally performant solutions to existing problems. There remains much to be done towards the center of the spectrum, in the underserved domain of applied research focused on the interplay of machine learning algorithm performance with dataset quality, quantity, complexity, provenance, and veracity.
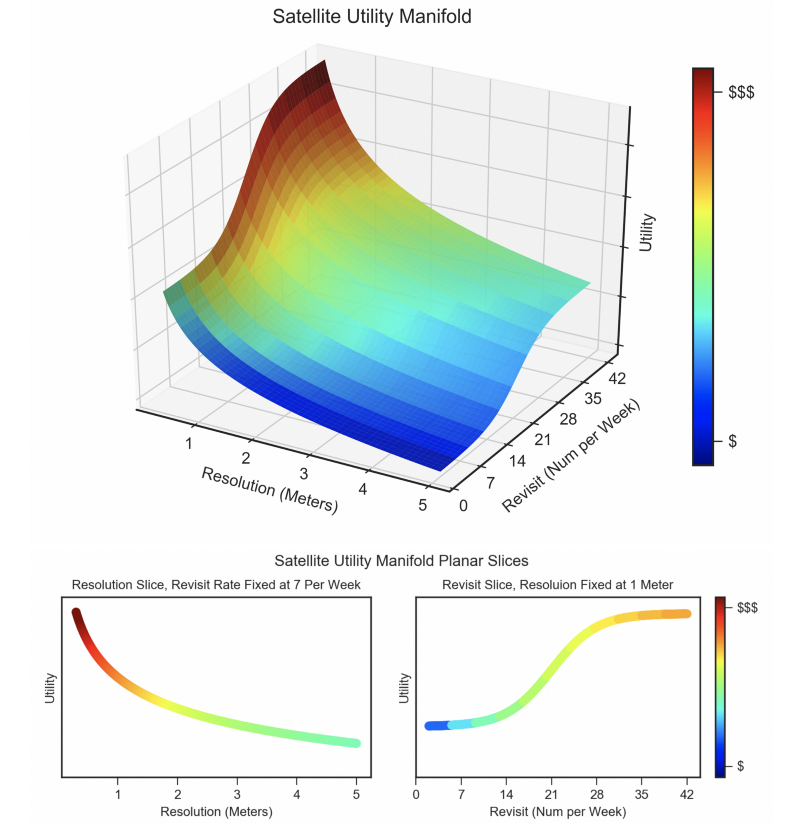
Conducting applied research on the interplay of machine learning and dataset facets informs a number of strategic questions, such as what type of sensor hardware is required for data collection, or how much effort is required to collect and validate novel datasets. In the following sections we explore a few of the many possible axes of import to geospatial analytics.
2. Sensor Resolution
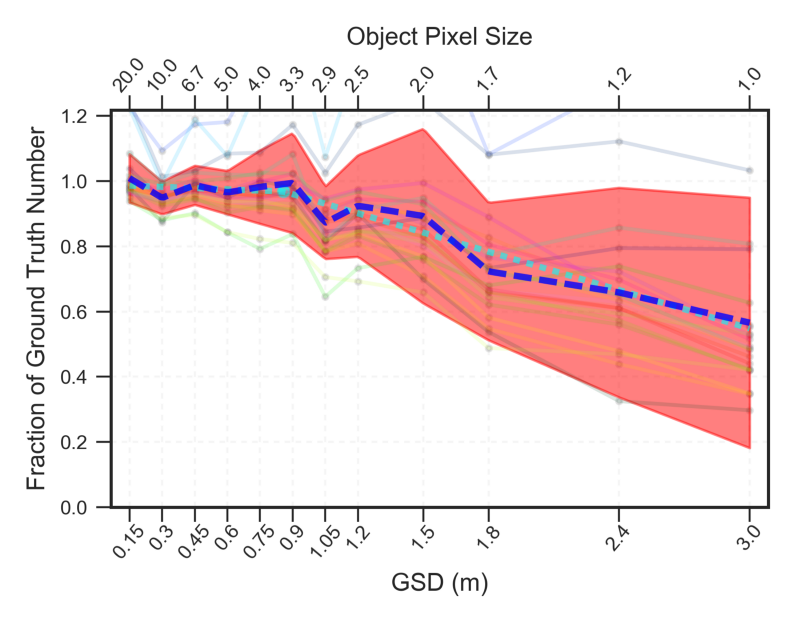
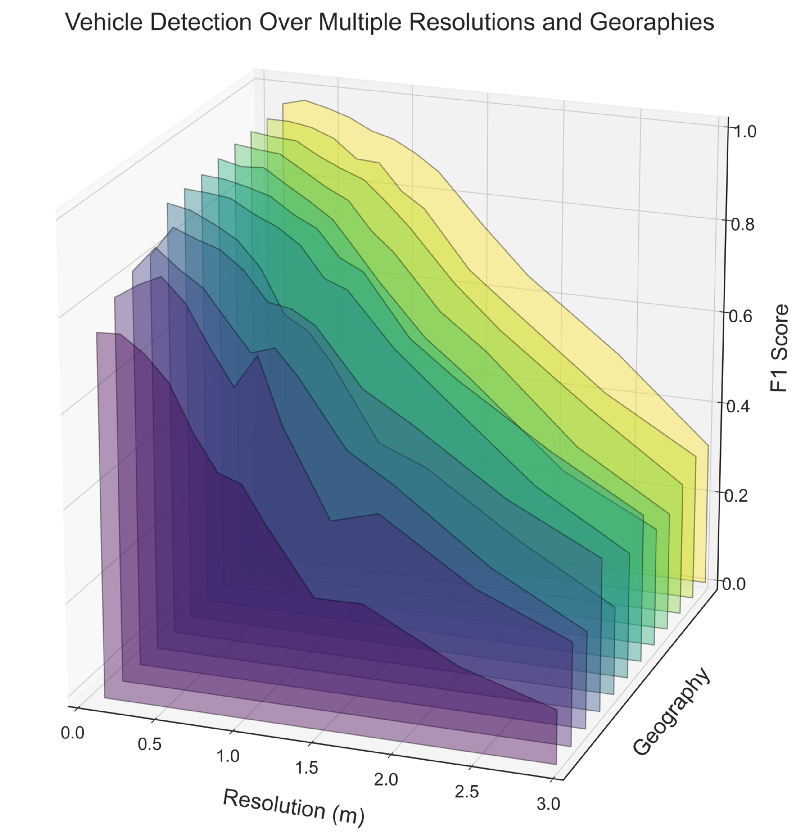
One method for measuring the utility of satellite imaging constellations is object detection performance. CosmiQ Works’ first foray into formally exploring the utility manifold quantified the effects of image resolution on vehicle object detection, with the aim of providing a cross-section of the manifold and informing tradeoffs in hardware design. This study demonstrated that for the selected dataset, detection performance reached an inflection point for objects ∼ 5 pixels in size, see Figure 2.
This early work holds up well against more recent (July 2020) work conducted by industry: compare the object enumeration performance of Figure 2 with the final figure of this Maxar blog. At 60 cm resolution the recent Maxar analysis records a recall of only 0.03, whereas our analysis in Figure 2 has 35✕ better performance, with a recall of 0.97. The salient point here is: while manifold studies are starting to interest industry, clearly much work remains to be done. Further information is available in the arXiv paper, and in previous blogs [1, 2, 3].
Expanding upon the initial work on resolution, CosmiQ undertook a detailed study on the application of super- resolution techniques to satellite imagery, and the effects of these techniques on object detection algorithm performance applied to terrestrial and marine vehicles. Using multiple resolutions and super-resolution methodologies, this work showed that super-resolution is especially effective at the highest resolutions, with up to a 50% improvement in detection scores. Further information is available in the CVPR EarthVision paper, as well as a series of blogs [4, 5, 6].
3. Limited Training Data
n most machine learning applications, training data is a precious resource. With this motivation, CosmiQ Works undertook a Robustness Study to determine how training dataset size affects model performance in the geospatial domain, specifically: the task of finding building footprint polygons in satellite imagery. The study indicated that model performance initially rises rapidly as training data is increased, with diminishing returns as the amount of training data is increased further.
In fact, compared to using the full data set, using just 3% of the data still provides 2/3 of the performance, see Figure 3. Irregardless of domain, a better understanding of the relationship between dataset size and predictive performance has the potential to help guide decision-making surrounding data collection and analysis approaches. Further details are available as a booklet, as well as a series of blogs [7, 8, 9, 10].
Currently, the standard approach for training deep neural network models is to use pre-trained weights as a starting point in order to improve performance and decrease training time, an approach called transfer learning. Given its ubiquity, quantifying the boost provided by transfer learning is therefore of great importance. A transfer learning study undertaken by CosmiQ Works showed that while pre-trained weights yielded abysmal results when applied to a new testing corpus, transfer learning using these weights allowed the model to rapidly (i.e. in the span of ∼ 5 minutes) train on the new domain, yielding marked improvements in performance. Such findings not only inform the utility of transfer learning, but the amount of data required to adapt pre-trained weights to new environments.
The Rareplanes synthetic data study looked at another important computer vision problem: how much data is required to detect rare objects (airplanes, in this case) in a large dataset. See the following section for further discussion.
4. Synthetic Data
Rareplanes is a machine learning dataset and research study that examines the value of synthetic data to aid computer vision algorithms in their ability to automatically detect aircraft and their attributes in satellite imagery. CosmiQ curated and labeled a large dataset of satellite imagery (real data), to go along with an accompanying synthetic dataset generated by an IQT portfolio company. Along with the dataset, the Rareplanes project provided insight into a number of axes, such as the performance tradeoffs of computer vision algorithms for identification of rare aircraft that are infrequently observed in satellite imagery using blends of synthetic and real training data (see Figure 4). Further details are available in the arXiv paper, as well as a blog series [11, 12, 13, 14].
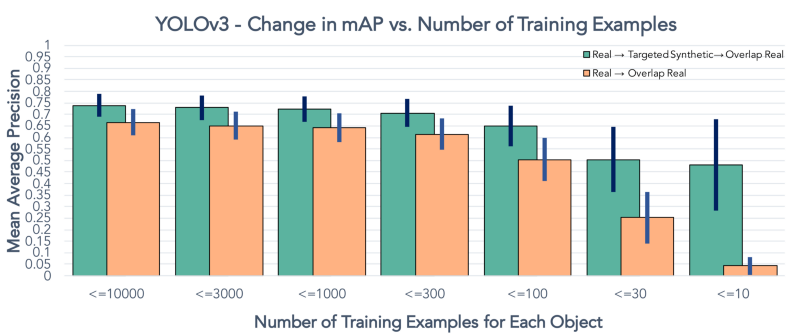
5. Observation Angle
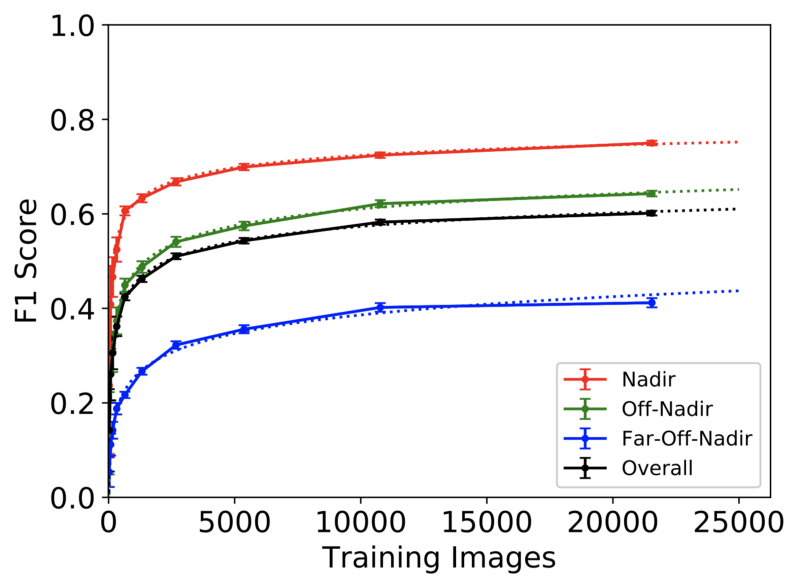
In many scenarios where timeliness is key, remote sensing imagery cannot be taken directly overhead (nadir), necessitating data collection from an off-nadir perspective. The vast majority of remote sensing datasets and models are nadir, however, leaving a significant gap in understanding as to how state-of- the-art algorithms perform in non-ideal scenarios such as high off-nadir imagery. To address this question CosmiQ launched the SpaceNet 4 dataset and challenge (see the ICCV paper for further details). The dataset consisted of multiple collections of the same location (Atlanta, Georgia) as a satellite passed overhead, yielding 27 different nadir angles in the dataset. This allowed the CosmiQ Works team (and SpaceNet 4 competitors) to quantify the drop in building footprint detection performance as the “quality” of imagery degrades as imagery becomes more and more skewed.
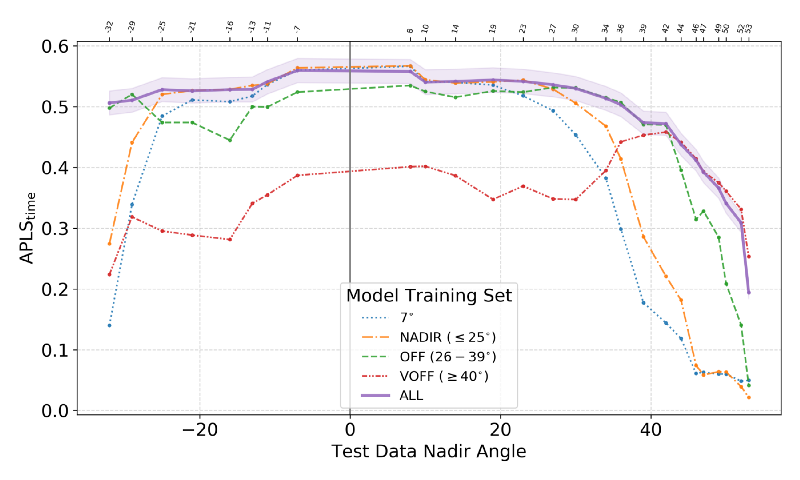
Subsequently, the CosmiQ Works team performed a similar analysis of the Atlanta dataset, this time extracting road networks from highly off-nadir imagery, demonstrating the ability to identify road networks and features at off-nadir angles (see Figure 5). Somewhat surprisingly, road networks appear easer to extract at high off nadir angles than buildings, see the arXiv paper for further details. The performance benchmarks established by both the buildings and roads studies have the potential to inform collection management procedures, as well as satellite constellation design.
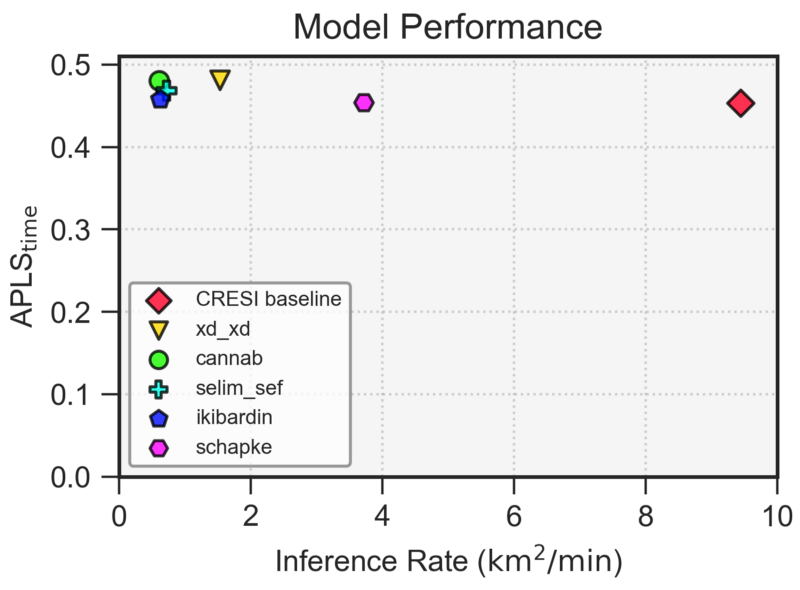
6. Speed / Performance Tradeoffs
The final piece of the utility manifold we will discuss is the tradeoff of algorithm performance and runtime. Frequently, the state-of-the-art in machine learning is advanced by adding layers of complexity to existing models, thereby netting a 2 − 5% improvement in the metric of choice (and an academic paper), but at the expense of increased runtime. Such “advances” sometimes turn out to be detrimental for real-world use cases due to slower speeds and increased fragility. These tradeoffs have been analyzed for the SpaceNet 5 road network and travel time challenge [16] (see Figure 6 below), as well as the SpaceNet 6 synthetic aperture radar (SAR) building extraction challenge [17]. These analyses allow potential users of the open source code provided by these efforts to benchmark performance and to determine the appropriate algorithmic approach based on their performance requirements and computational environment.
7. Conclusions
In the satellite analytics domain, myriad questions can be asked once a suitable measure of utility is decided upon, and quite often the least interesting (though most commonly pursued) research topic is building a machine learning model that maximizes utility without addressing the underlying feature space that determines performance. Studying the performance curve along various axes yields far more insights than just a single datapoint denoting maximum performance. Combining multiple facets together also permits quantification of the complex multi-dimensional utility manifold. This concept is illustrated in Figure 7.
Many of the lessons learned and research questions from the geospatial analytics discussed above translate readily to new domains. For example, some axes are universally important such as data resolution, label resolution, and dataset size. Measures of utility will of course vary across domains, but it is possible that manifolds may hold predictive power across domains.
Creating new datasets is often a critical piece of manifold studies (see the Appendix in the corresponding paper). For context, precisely zero of the examples above had the luxury of analyzing existing datasets; in all cases answering the pertinent question necessitated the curation of a new dataset with the requisite features.
In our estimation, exploring the feature space that determines machine learning performance on high quality datasets remains an understudied, yet highly impactful research area. Quantifying the extent to which machine learning performance depends upon and influences dataset size, fidelity, quality, veracity, and provenance has the potential to positively impact the complex missions of a broad array of customer groups at both the tactical and strategic levels. For greater detail and exploration of further axes of interest not discussed here (e.g. label quality, object properties, imaging band cardinality, data diversity, etc), feel free to to review our full paper.
* Acknowledgements: The work summarized here stems from research conducted by Ryan Lewis, Jake Shermeyer, Daniel Hogan, Nick Weir, Dave Lindenbaum, Lee Cohn, and the author.