


Approaches to Protecting the Software Supply Chain
If you use software, then you reap the rewards of code reuse, which is the now widespread practice of repurposing existing software components to build new software. This concept dates back to the late 1960s and has been a goal of software engineers because of its potential to streamline the process of building, releasing, and improving software. These goals have finally been realized over the past decade. Widespread usage of open source software libraries and maturity of package managers for popular software languages have combined to produce irreversible changes in developer behavior that make the avoidance of code reuse completely impractical in modern software development environments.
But there’s a catch: Code reuse has security risks. Information security research scientist Sandy Clark and her co-authors report that reusing code can actually increase the number of vulnerabilities found in a piece of software due to a lack of familiarity with reused components. A July 2020 analysis by the Atlantic Council’s Trey Herr and his colleagues found over 80 reported software supply chain attacks executed by state actors, i.e., deliberate efforts to embed malicious code into a software product, attacks with payoffs that increase as a function of amount of component reuse. This report details a noticeable increase over the past decade, especially the last five years, in attacks on the software supply chain. Adding to the evidence of an increase in software supply chain attacks, earlier this year ReversingLabs found over 760 malicious Ruby packages in the RubyGems package registry and a research team at Georgia Tech discovered over 300 malicious packages in PyPI (Python), npm (Javascript), and RubyGems combined. These compromised packages perform such nasty actions as stealing your credentials or your keystrokes and are frequently available for download for months before they are identified and removed from the package registry.
Given the dangers of insecure code reuse, a variety of organizations and individuals are rising to the challenge. But more can, and in our opinion, should be done. To help make sense of secure code reuse, this post first describes a framework for delineating and assessing potential new initiatives with later sections assessing the costs and effectiveness of each approach.
Importantly, we are not advocating that you or your organization stop using open source software. Many of the risks of code reuse apply to both open source and closed source, or proprietary, code. Nor is this a rebuke of code reuse. We are proposing a research program to increase secure code reuse.
Comparing Approaches to Secure Code Reuse
Promoting secure code reuse is no simple task. There are billions of software users involved, countless firms, questions of habit and political ideology, and unsolved technical issues that require advancements in computer science or software engineering to address. Additionally, there are several relevant initiatives already underway. To avoid paralysis by analysis, we decided to start simple. Others should critique and build upon the framework we describe below.
We start by stating the primary activities that are relevant to secure code reuse: security research, open source contribution, and software consumption. Security research involves the discovery of supply chain compromises already present in the software ecosystem, either by directly searching for these compromises or building the scientific base and applied tools to better search for these compromises. Open source contributions improve the ecosystem that facilitates widespread code reuse, to include the open source codebase, software repositories that host source code, package registries that store software components, and package managers that control packages used as dependencies of an application. Software consumption focuses on selecting, acquiring, and using externally developed code while simultaneously balancing security risks and coding efficiency.
To compare projects associated with these activities, we propose four criteria:
- How significant are the external organizational and administrative challenges to implementing a specific project?
- How significant is the research challenge?
- How significant is the development challenge?
- Finally, how many people (software developers and end users) could be affected?
See Figure 1 for an application of this framework to six different projects related to enabling and promoting secure code reuse. To provide answers for each question for each project, we used our own best judgment to estimate the challenge for an independent research organization with a small staff. Other researchers and organizations might have different perspectives. The next section explains these projects and compares their relative merits.
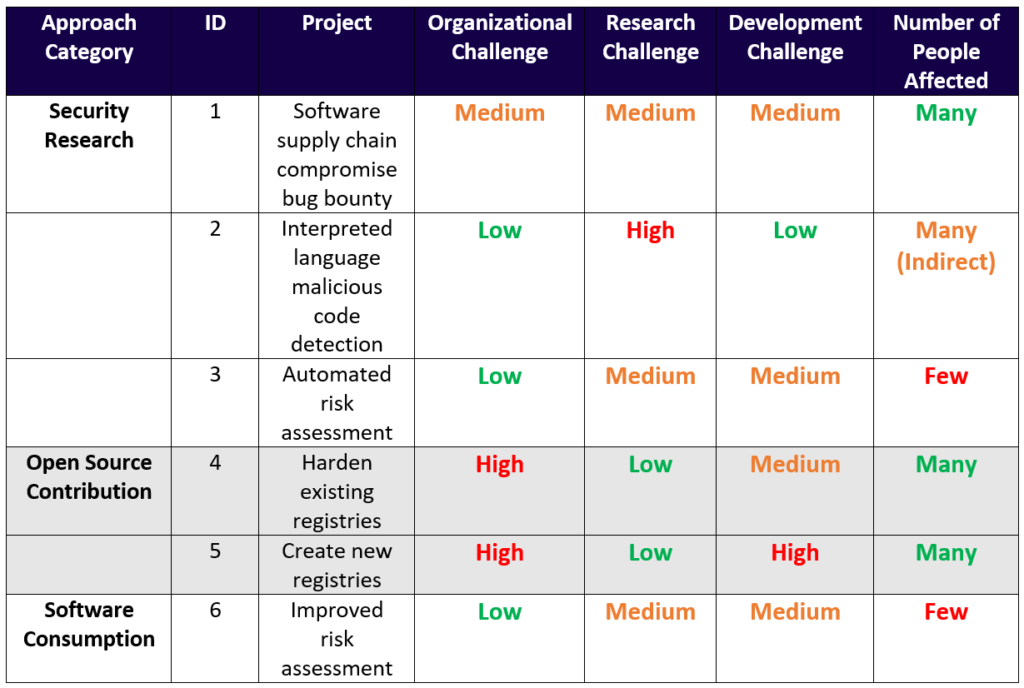
Security Research Approaches
Identifying software supply chain compromises (project ID #1) and building tools that enable others to do so (project ID #2 and #3) is an essential component of secure code reuse. This is a technically challenging domain that requires require skill and knowledge, but it offers the reputational gains traditionally associated with finding compromises and, potentially, monetary awards, if one of the ideas below came to fruition.
One approach involves extending the idea of a bug bounty so that participants could earn cash prizes and recognition for their discovery of software supply chain compromises. Sponsoring such a competition could not only lead to identifying and remediating currently undetected compromises, benefitting many software developers and users directly, but could also help generate tools to support such a task. A recent tool developed by IQT Labs called pypi-scan, which scans PyPI for potential typosquatters, is an example of a tool that might be created as individuals and teams hunt for software supply chain compromises. Tidelift’s open source software package data experiments, while not aimed at finding malicious dependencies, are another analytical precedent for this type of activity.
Another line of effort, which entails significant technical challenges, would involve building the scientific knowledge and engineering tools to detect malicious code in interpreted languages, those programming languages that directly execute code and which form essential pillars of the software reuse ecosystem. Tools such as bandit help detect vulnerabilities in, for instance, Python, but relatively few tools, and even fewer open source tools, currently aid in the search for compromised packages. Part of the difficulty of this approach will be assembling a corpus of both normal and compromised packages, dataset design decisions that are tricky but not impossible.
Additionally, tools that automatically and continuously assess each software component’s provenance and security risks can support more thorough risk analysis, but much of the metadata relevant to software supply chain security is not currently included in that process. Imagine, for instance, a Dependabot that does more than simply scan dependencies for being out of date or having reported vulnerabilities. Alternatively, imagine a ruleset, along the lines of DangerJS, that enforces a comprehensive software reuse hygiene checklist. Ph.D. student March Ohm and his colleagues have investigated a facet of such an approach by examining the extent to which software supply chain attacks create new artifacts. This post-build tool would share many of the same characteristics as the pre-build tool described later, but it would be better suited to dealing with the rapid software updates associated with modern software development practices.
Open Source Contributions
Improving the security practices and postures of open source package registries and software repositories (project ID #4 and #5) that are the source of most software components in use today is a logical option. Hardening these platforms, such as PyPI, npm, and RubyGems or GitHub and GitLab, entails building anti-malware checks and other software assurance checks into these repositories or source code management platforms. PyPI has recently installed an anti-malware pipeline and potential contributors should consider adding new anti-malware checks to that pipeline. GitHub recently made a code scanning tool to find security vulnerabilities generally available. Remaking these platforms could require building new infrastructure that either amends or replaces these repositories and the associated package managers that actually download and install the code on your computer. To be sure, there are other approaches farther upstream, such as creating and promoting secure programming languages and grant-making by the federal government for certain open source software packages. These sort of would-merit-the-Turing-Award or political options are simply beyond the reach of most organizations, and so we do not explore them in depth.
While approaches that address issues within package registries and software repositories have the advantage that any security improvements will have massive, direct benefits for secure code reuse, there is a notable hurdle. Proposing and making changes to these registries require working in or with ecosystem maintainer organizations, such as the Python Software Foundation for PyPI or GitHub for npm. Any entity proposing changes will need to craft their proposal to be congruent with the interests of the associated community. There will be some technical hurdles too, given that these platforms are generally reluctant to raise barriers to access, perceived or otherwise. And if you want to create your own new repository or package manager devoted to secure code reuse, you’ll have to compete with incumbents and face the challenge of attracting new users. While many of these obstacles are daunting, organizations like the Linux Foundation are tackling these issues with efforts such as their core infrastructure initiative.
Helping Software Consumers
Some developers and organizations will simply want to protect their own operational environment (see project ID #6). It’s politically simpler and potentially even technically simpler to detect software supply chain compromises that impact your own codebase and infrastructure and remediate these yourself.
The key for those who embrace this approach is risk assessment and management. What is the provenance of your code and what assurances do you have—technical and non-technical—that you can trust other’s software components? Cautious developers and skeptical chief information officers (CIOs) could employ tools, mostly yet to be built, that enable this assessment. Such workflows can mine the data of open source software: commits, package maintainers, contributors, and whatever else is entangled in this online web. An early-stage tool developed by IQT Labs, called pkgscan, enables such an approach towards Python packages from PyPI. Potential projects also include building a framework and associated tools for CIOs and security-conscious developers to determine the risks of using a given open source project or package.
Commitments before Commits
These approaches offer many choices to organizations both large and small contemplating a project on secure code reuse, especially a project on detecting and combatting malicious vulnerabilities. Each has their own challenges to be sure, but the rewards seem to outweigh any potential risk to individuals or organizations with the ability to contribute. Of course, some of these tasks are better suited for larger, better funded organizations: improving interpreted language malicious code detection, for instance, or a comprehensive software supply chain security bug bounty. You can also opt out completely, avoiding dependence on any and all software. If so, close this browser and we wish you god speed. For everyone else, you’ll have to stand on the shoulders of researchers and developers past and ask not what secure code reuse can do for you, but what you can do for secure code reuse.
Thank you to Ben Baumgartner for doing his best to help us make the waters less muddy, Luke Berndt for constructive critique and his role as outside provocateur, Peter Bronez for thoughtful conversation and smart suggestions on this topic, and Mike Chadwick for encouragement and helpful pushing.