

VOiCES at Speech Odyssey 2020: Advances in Speaker Embeddings
At Speech Odyssey 2020 IQT Labs sponsored a special session on applications of VOiCES, a dataset targeting acoustically challenging and reverberant environments with robust labels and truth data for transcription, denoising, and speaker identification. In the next two blog posts we will be surveying the papers that were accepted to this session.
Following the overall theme of Speaker Odyssey, the accepted papers focused on improving the robustness of speaker verification (SV) systems, with respect to environment noise and reverberation. Speaker verification (also referred to as speaker authentication) is the task of deciding whether or not a segment of speech audio, or utterance, was spoken by a specific individual (target speaker). Thus SV is a binary classification problem and performance can be characterized in terms of the rate of type I and type II errors, false rejections and false acceptances respectively, or visually summarized in plots of the false rejection rate vs. the false acceptance rate for different values of the decision threshold, known as detection error tradeoff (DET) curves. In the biometrics field, two statistics are commonly used to reduce the information of a DET curve to a scalar performance metric:
- Equal Error Rate (EER): The intersection of the DET-curve with the diagonal, or the value of the false rejection rate and false error rate when the two are equal.
- minDCF: The detection cost function (DCF) is a weighted sum of the false rejection and acceptance rates, where each rate is weighted by a prescribed penalty for that type of error and the probability of the target speaker being/not being present. minDCF is the value of DCF when the decision threshold is set optimally. See here (section 2.3) for more discussion.
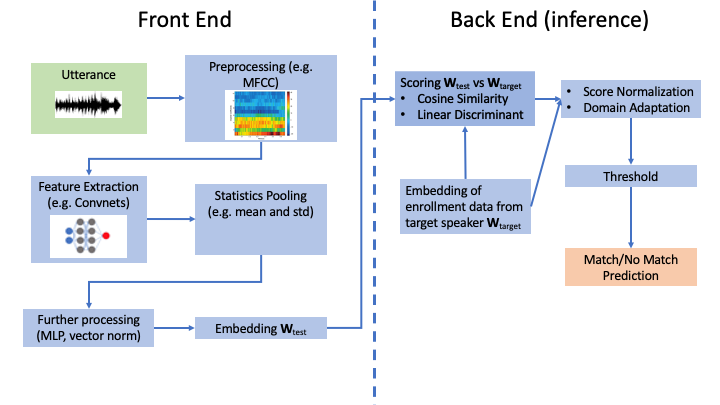
Typical text-independent speaker verification systems operate by computing a “score” that measures how similar an utterance is to speech audio obtained from the target speaker, also known as enrollment data. This is done in two parts: A front end that produces a fixed-length vector representation of variable length utterances, known as a speaker embedding, and a back end that computes the score between the test embedding and embedding of the enrollment data, typically using cosine similarity. Prediction is then a matter of thresholding the score. However, for systems that are designed to work for many different target speakers and in varying environments the score distribution can vary wildly between speakers and conditions. To counteract this, score normalization is used to standardize the score distribution between speakers, usually by normalizing the raw scores with the statistics of the score between the test/enrollment embedding and the embeddings of many other target speakers. Similarly, domain adaptation is used to match the statistics between embeddings produced in differing acoustic conditions.
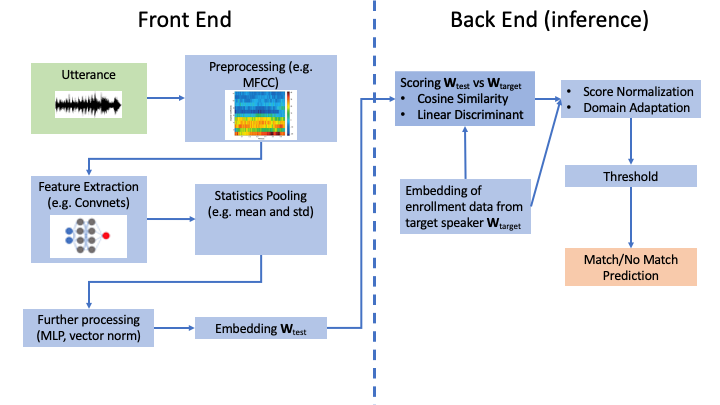
The front end itself is composed of several steps including voice activity detection, feature extraction, and statistics pooling. Recent performance advances have come from training deep neural networks to perform some or all of these steps, using large datasets of speaker-tagged utterances, producing deep speaker embeddings. In this post we will summarize the three papers accepted to this session focused on techniques for improving deep speaker embeddings.
Mixture Representations for Speaker Embeddings
The first paper, “Learning Mixture Representation for Deep Speaker Embedding Using Attention” by Lin, et al. addresses the statistics pooling step of speaker embeddings. Most speaker embedding systems, particularly those involving deep neural networks, extract a fixed-dimensional feature vector for each frame (e.g., time window in a spectrogram) of an utterance. Because utterances vary in length, the lengths of these feature vector sequences will also vary. As speaker embeddings are elements of a vector space, there must necessarily be a point in the algorithm where the sequence of frame level features is reduced to a vector of constant dimension, which is called statistics pooling. Many state-of-the-art (SOTA) speaker verification systems are based around the X-vector approach which uses deep neural networks for feature extraction and performs statistics pooling by concatenating the mean and (diagonal) standard deviation of feature vectors over the course of the utterance.
Because some frames in an utterance may be more speaker-discriminative than others, previous authors have suggested augmenting the X-vector approach using attention to weight the frame level features before computing the mean and standard deviation. This approach, attentive statistics pooling (ASP), can be generalized to the case of multiple attention heads, with a separate mean and standard deviation vector for each head. Lin et al claim that multi-headed ASP alone does not create a richer representation with more attention heads and instead propose a modification where the attention scores are normalized across heads at the frame level. After some normalization, the resulting mean and standard deviation vectors produced at the statistics pooling step are analogous to the component parameters of a gaussian mixture model with one component for each attention head. They denote this method as mixture representation pooling (MRP).
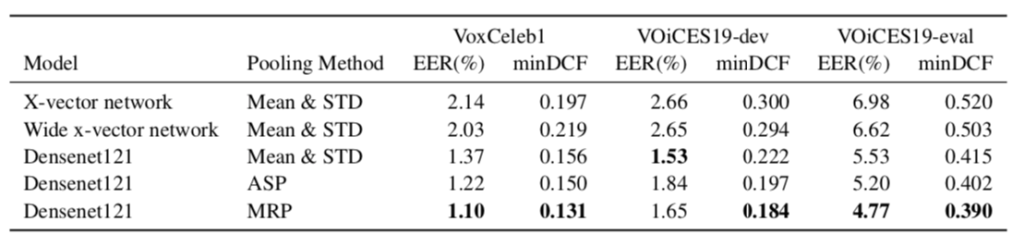
The authors ran several experiments to demonstrate the effectiveness of MRP over ASP and X-vector. They use the Densenet architecture as a feature extractor network for ASP and MRP, as well as for a baseline mean and standard deviation statistics pooling. The EER and minDCF are evaluated for each approach on VoxCeleb1, VOiCES19-dev, and VOiCES19-eval. Importantly, for multi-headed ASP and MRP, they scale the dimensionality of mean and standard deviation vectors inversely with the number of heads for a fairer comparison in terms of the number of parameters. They find that in almost all cases, MRP with three attention heads performs the best.
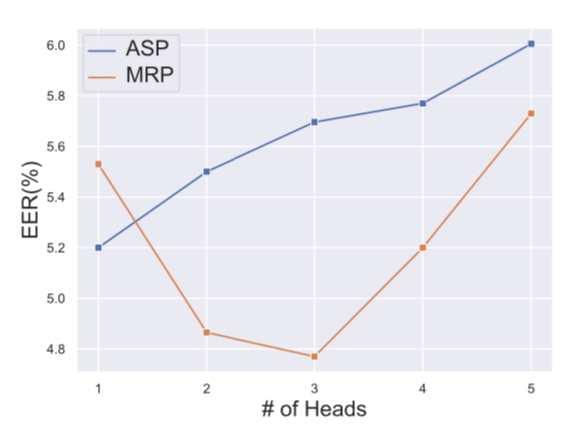
Furthermore, to reinforce the author’s intuition that multi-headed ASP doesn’t make proper use of extra attention heads they compare the performance of ASP and MRP on VOiCES19-eval as a function of the number of heads. They find that ASP performs best with just one head, whereas the optimal number of heads for MRP is three.
Improving Pipelines for Deep Speaker Embeddings
The second paper “Deep Speaker Embeddings for Far-Field Speaker Recognition on Short Utterances” by Gusev, et al. explores a variety of choices of system architecture, loss functions, and data preprocessing with the aim of improving the performance of SV systems on both distant speech and short utterances. They evaluate different combinations of these design choices on the VOiCES and VoxCeleb test sets, for both full utterances and utterances that have been shortened to 1, 2, and 5 seconds, and arrive at several conclusions:
- Performing voiced activity with a U-net based model that is trained end-to-end outperforms the standard energy-detection based model in the popular automatic speech recognition toolkit Kaldi.
- Data augmentation improves performance. In particular, when adding noise and reverb to clean utterances, it is important to apply reverb to both the noise and speech.
- It is better to perform frame-level feature extraction with a neural network based on the ResNet architecture than the X-vector architecture, which is based around time-delay neural networks. This holds true even when the X-vector network is augmented with recurrent connections.
- Higher dimensional acoustic input features increase performance. Specifically 80 dimensional Log Mel-filter Bank Energies lead to better performing models than 40 dimensional Mel Frequency Cepstral Coefficients.
- Finetuning SV models on reduced duration utterances decreases their performance on full length utterances, so there is a fundamental tradeoff in performance between these two application domains.
Selective Embedding Enhancement
The final paper to touch on deep speaker embeddings was “Selective Deep Speaker Embedding Enhancement for Speaker Verification” by Jung et al. While deep speaker embeddings have led to high SV performance on utterances recorded at close range and in clear conditions, their performance degrades considerably on speech with reverberation and environmental noise. At the same time, systems trained to compensate for noisy and distant speech underperform on clean and close speech, as we reported in a previous blog post for automatic speech recognition. Furthermore, every newly proposed system for speaker embeddings has to be separately fine-tuned and calibrated for noisy utterances. In light of these concerns, Jung et al. propose two systems to enhance speaker embeddings that satisfy the following three desiderata:
- The systems can be applied to utterance examples that range from close talk to distant speech and are adaptive to the level of distortion present.
- These systems operate directly on the embeddings produced by front-end speaker embedding systems and treat the speaker embedding systems as a black box model.
- The architectural complexity and computational cost of inference are minimized.
To train and test the proposed systems, Jung et al. used the VOiCES dataset because it contains many different distant speech utterances corresponding to a given close-talk (source) utterance and the underlying source utterances are also available for training/testing data.
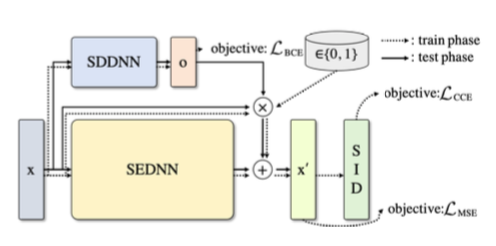
The first system they propose, skip connection-based selective enhancement (SCSE), utilizes two deep neural networks to perform distortion-adaptive enhancement of speaker embeddings from the front-end, represented as x in the figure. The first network, SDDNN, is trained as a binary classifier to distinguish source utterances from distant utterances. The second network, SEDNN, outputs a “denoised” version of the embedding. The original embedding x is multiplied by either the output of SDDNN (at test time) or a binary source/distant label (during training) and added to the output of SEDNN to produce the enhanced embedding x’. To encourage SEDNN to behave like a denoising system, the training includes a mean squared error loss between x’ and either x, if x came from a source utterance, or the embedding of the corresponding source utterance if x came from a distant utterance. Finally the whole system is trained with categorical cross entropy to ensure that the enhanced embeddings are still informative about speaker identity.
The second system is based on the discriminative auto-encoder framework, and denoted as selective enhancement discriminative auto-encoder (SEDA). The input embedding, x, is passed through a pair of encoder and decoder networks producing the reconstruction y. Like in SCSE, the reconstruction target for y depends on whether x is the embedding of a source or target utterance. Additionally, during training, y is trained to be speaker-discriminative with a categorical cross entropy loss, though y is not used as the enhanced embedding. The encoding of x produced by the encoder network is partitioned into two components, x’ and n, where x’ is the enhanced embedding used at test time and n contains information about nuisance variables such as noise and reverberation. The distribution of enhanced embeddings x’ is regularized with two loss functions to make sure that embeddings information about the speaker and minimal nuisance information. The first loss function, center loss, penalizes the average euclidean distance between an embedding and the mean vector of all embeddings corresponding to the same speaker. The second regularizer, internal dispersion loss, maximizes the average distance between an embedding and the average vector over all embeddings. When combined, these two loss functions minimize intra-class variance and maximize inter-class variance.
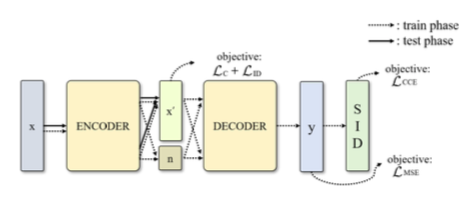
The enhanced embedding x’ is regularized with two loss functions to make sure that it contains information about the speaker and minimal nuisance information: Center loss and internal dispersion loss.
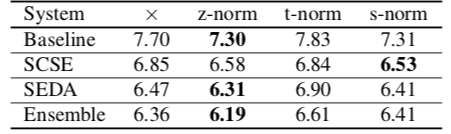
Jung et al. used a slightly modified version of the RawNet speaker embedding architecture as the embedding front-end for all their experiments. RawNet operates on raw waveforms, performs feature extraction with a series of convolutional and residual layers, and does statistics pooling with a gated recurrent unit (GRU) layer. The authors performed extensive hyper-parameter optimization for SCSE and SEDA, and compared the performance of the two systems to a baseline that uses the embeddings produced by RawNet with no enhancement. Additionally, they experiment with multiple types of score normalization and with ensembling the two systems by summing the embedding scores. They find that z-norm score normalization and ensembling result in the optimal performance.
Conclusion
Though none of their approaches match state of the art EER on VOiCES, compared to the performance of teams in the Interspeech 2019 VOiCES from a Distance Challenge, achieving competitive performance on noisy data without sophisticated denoising preprocessing while also maintaining performance on clean data is important for systems deployed in the real world.
Speaker verification systems based on deep speaker embeddings have recently demonstrated significant advances in performance. However, as all three papers surveyed in this post have demonstrated, different choices in architecture, data preprocessing, and inference procedure can strongly impact how a speaker verification system performs in the presence of noise. Developing robust systems requires data that reflect the realistic conditions they will be deployed in, such as the VOiCES dataset. We are excited to see how advances in deep speaker embedding will push forward the state of the art in speaker verification. In the next blog post we will review other papers from this session that explored other aspects of the SV pipeline, such as beamforming and learnable scoring rules.