

VOiCES at Speech Odyssey 2020 — part II: Advances in Speaker Verification
In our previous post on the VOiCES workshop at Speech Odyssey we covered some of the basics of speaker verification (SV) systems and focused on three accepted papers that studied different approaches to improve the front-end models used to extract deep speaker embeddings.
The second set of papers accepted to the VOiCES workshop at Speaker Odyssey 2020 studied a variety of problems in far field SV: disentangling speaker embeddings, learnt scoring for improved back-ends and trainable beamforming for multi-channel SV systems.
Empirical analysis of speaker embeddings
Constructing an effective SV system hinges on capturing features that are relevant to distinguishing a specific speaker while being robust to other sources of variability that are unrelated to the speaker’s identity, for instance the acoustic environment, microphone characteristics, and even the lexical content of the speech.
In the paper “An empirical analysis of information encoded in disentangled neural speaker representations” Peri et al. discuss an extension of their previous work where they proposed an approach to induce such robustness by disentangling speaker-related factors from other factors. In this submission they focus on an in-depth analysis of the effect of utilizing such an approach on the VOiCES dataset as well as the extent at which these different factors are entangled in speaker embeddings.
The authors draw a distinction between three classes of sources that ultimately contribute when building a deep representation of human speech:
- Channel factors: This category includes sources of variability coming from acoustic conditions, microphone characteristics, background noise, etc., and it has been extensively studied in literature related to SV in the context of building systems that are robust to this sort of variability.
- Content factors: These factors encode information about the spoken content itself, such as prosodic variations in speech, lexical content and sentiment. Previous work has shown, unsurprisingly, that these factors can be deeply entangled with speaker-specific factors.
- Speaker factors: These factors are, ideally, those that capture the identity of a specific person and are enough to fully distinguish one speaker from another.
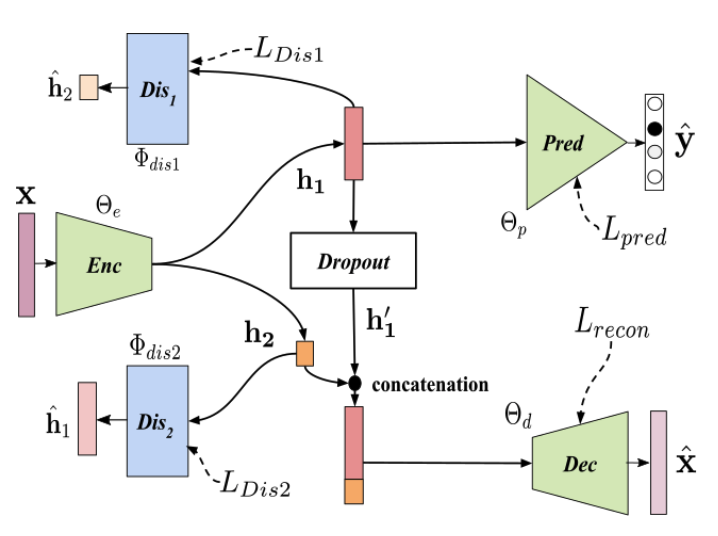
The authors analyzed the effect of entangled representations by comparing embeddings from a series of different approaches. As a baseline they used x-vectors from the publicly available Kaldi software package trained without any explicit disentangling of factors, and compared to models based on their previous work UAI (illustrated in the Figure 1) trained to isolate speaker-specific characteristics.
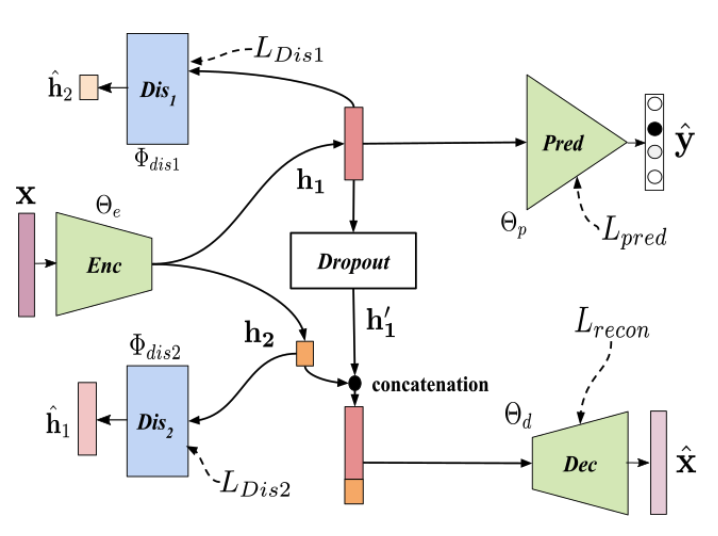
The authors used these frameworks to study the amount of speaker, channel and content information in each of the embeddings. They trained a set of simple feed-forward networks to ingest these embeddings and predict different factors such as room, microphone, emotion, speaker, etc. The authors leveraged a series of datasets (VOiCES, IEMOCAP, MOSEI, RedDots & Mozilla) to study a total of nine factors.
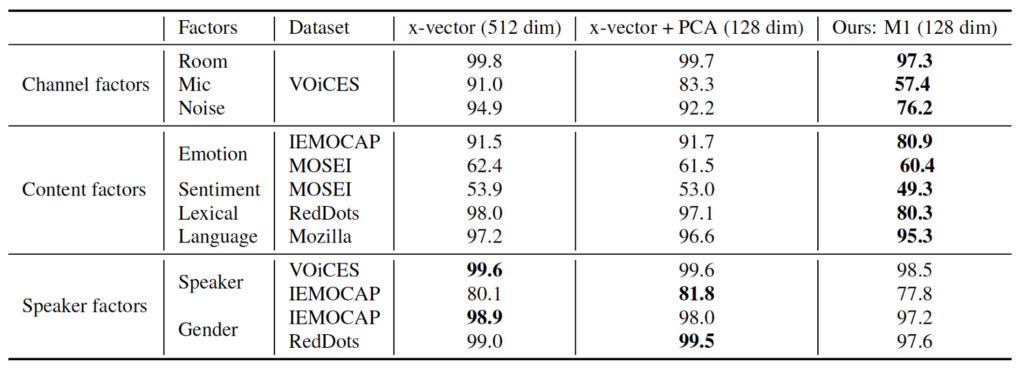
Table 1 shows a breakdown of the model accuracy on predicting a given factor as well as the dataset used for the studies. Ideally, embeddings that have fully isolated the speaker-specific attributes from other factors should perform well in predicting speaker factors (gender and speaker) while doing a poor job on the task of classifying channel and content factors. The results from Peri et al. show precisely that, their disentangled UAI model embeddings have the lowest performance against all channel and content factors with a relatively small drop in accuracy on the prediction of speaker factors. These disentangled representations can provide more robust speaker embeddings, more interpretable predictions and potentially reduce model sizes by encoding only the necessary information.
Learning to score in speaker verification systems
As we discussed in the previous post, the current state-of-the-art approaches to SV consist of employing a neural network (NN)to extract speaker embeddings together with a back-end generative model tasked with determining whether or not a specific audio sample matches a target track.
For instance, in a common pipeline X-vectors (embeddings) are extracted from a test audio sample and then pre-processed using a variety of transformations (such as linear discriminant analysis, unit-length normalization, within-class normalization, etc.). The transformed embedding vectors are then modeled to determine whether they match an enrolled speaker. A common approach to score such similarity between a pair of enrollment and test embeddings is to model them using probabilistic linear discriminant analysis (PLDA)and compute the log likelihood ratio between them.
In “NPLDA: A Deep Neural PLDA Model for Speaker Verification” Ramoji et al. discuss a novel approach to replace the PLDA back-end with a NN that jointly performs pre-processing and scoring trained using a SV cost, dubbed neural PLDA (NPLDA).
To train their neural backend, the authors used the publicly available VoxCeleb(1&2) datasets which consist of speech extracted from celebrity interviews available on YouTube. X-vectors were extracted by training a time delay neural network (TDNN) to discriminate among the nearly 7000 speakers in the corpus. Once trained, 512 dimensional embeddings were extracted from the second to last layer and used to determine whether a target and enrollment sample matched.
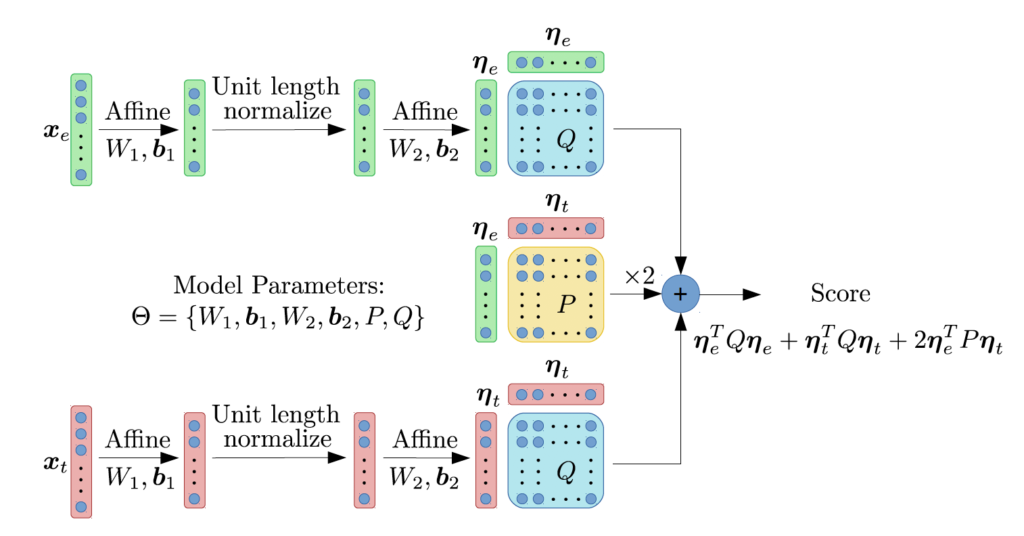
In the proposed pairwise discriminative network (Figure 2) the authors replace the pre-processing steps from a traditional LDA with an affine transformation layer, unit length normalization with a non-linear activation function and PLDA centering and diagonalization as a second affine transformation. The final, pair-wise scoring is implemented as a quadratic layer, and the whole pre-processing + scoring backend in NLPDA is learned using backpropagation. The authors experimented with two different cost functions:
- Binary Cross Entropy (BCE) is used as a baseline due to its simplicity to implement and differentiable nature. However, this loss alone is prone to overfit in such tasks.
- To improve on the results from using BCE, the authors propose a differentiable approximation to the normalized detection cost (DCF) dubbed soft detection cost. Using the soft detection cost allows to weigh the cost of both miss and false alarms in training the back end and reduce overfitting.
The NLPDA backend was compared to a series of previously used back-ends: Generative Gaussian PLDA (GLPDA), Discriminative PLDA (DLPDA) and a Pairwise Gaussian Backend (GB). The systems were trained using randomly selected (gender matched) pairs from the VoxCeleb corpus with and without data augmentation, and the performance was tested on the Speakers in the Wild eval set as well as the VOiCES dev and eval sets provided as part of the Interpseech 2019 VOiCES at a Distance Challenge.
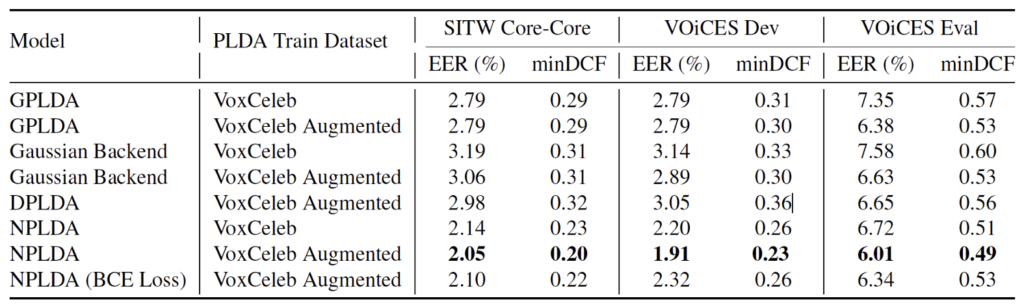
Table 2 shows the performance of the different systems on the datasets mentioned. The results show that, across the board, the learnt NPLDA approach (with soft detection cost) outperforms all other SV backends. These results illustrate the advantages of using a single, trained back-end to simplify both pre-processing and classification in SV systems, and sets the stage for future research into incorporating the front and back-end into a single, end-to-end SV system.
Beamforming techniques and the VOiCES challenge
Most of the accepted papers for the VOiCES workshop focused on single source audio for SV. However, even state-of-the-art approaches encounter difficulties when it comes to far-field audio, in particular in noisy and reverberant environments. Solving this problem by employing multichannel (microphone) approaches has received a great deal of attention, both within industry and academic research. One such approach focuses on using a beamforming front-end to de-noise and de-reverb the original multi-channel audio to produce a sanitized, single channel input prior to extracting speaker embeddings. In “Utilizing VOiCES dataset for multichannel speaker verification with beamforming” Mošner et al. leveraged the VOiCES dataset to benchmark their own NN generalized eigenvalue (GEV) beamformer.
As a baseline the authors use a weighted delay-and-sum beamformer implemented in BeamformIt toolkit, a fixed beamformer that doesn’t require any training. This baseline was compared with an adaptive GEV which estimates the beamforming weights via the learnt estimation of the input data statistics.
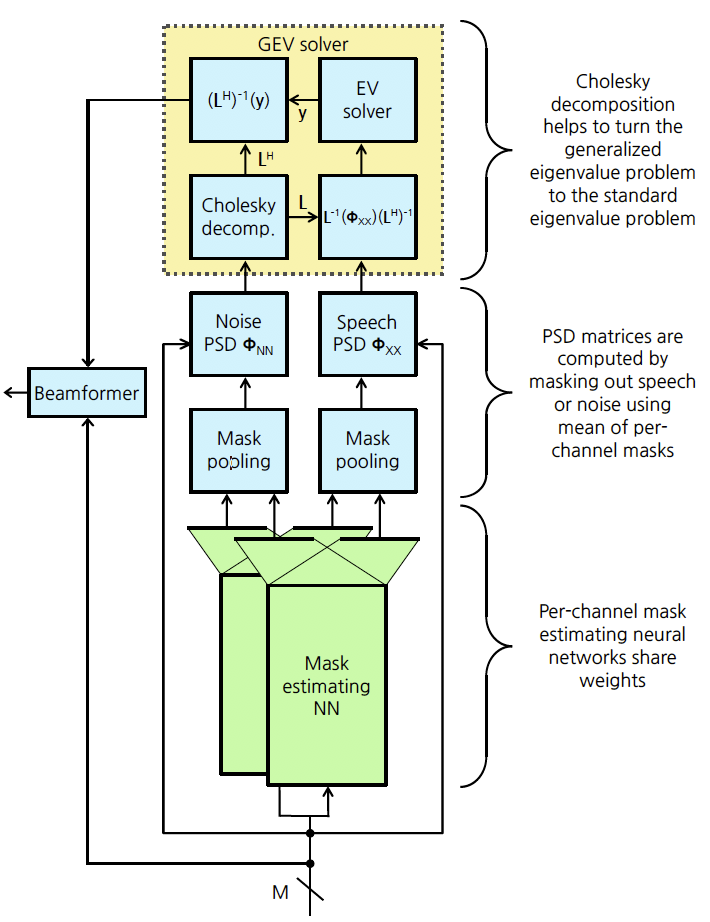
The full beamforming process is illustrated in Figure 3. NN’s are used to predict masks corresponding to the prevalence of noise or speech in the input audio. These predicted masks are then mean-pooled and applied to mask out noise or speech. The resulting matrices are fed to a generalized eigenvalue solver and the principal eigenvector is used as the beamforming weight vector. The authors studied two procedures to optimize the beamforming front end:
- BCE: The original procedure trains the NN’s by directly minimizing the binary cross-entropy (BCE) between the predicted and ideal noise and speech masks. Since this problem requires knowledge of the ideal binary masks for both noise and speech, the VOiCES corpus could not be used for training. Instead, the authors leveraged simulated data that resembled the VOiCES data via room simulation and addition of positional sources of noise.
- MSE: Using Cholesky decomposition to solve the eigenvalue decomposition allows backpropagation through GEV solver so it can be an integral part of the optimization procedure. The system can then be directly trained on the output of the beamformer. Here the objective function is the mean squared error (MSE) between the beamformer output and the clean speech audio. This approach has the added benefit that it can be trained directly on the VOiCES data.
In both of these approaches the NN-supported beamformer architecture is left unchanged and they vary only in the training procedure.
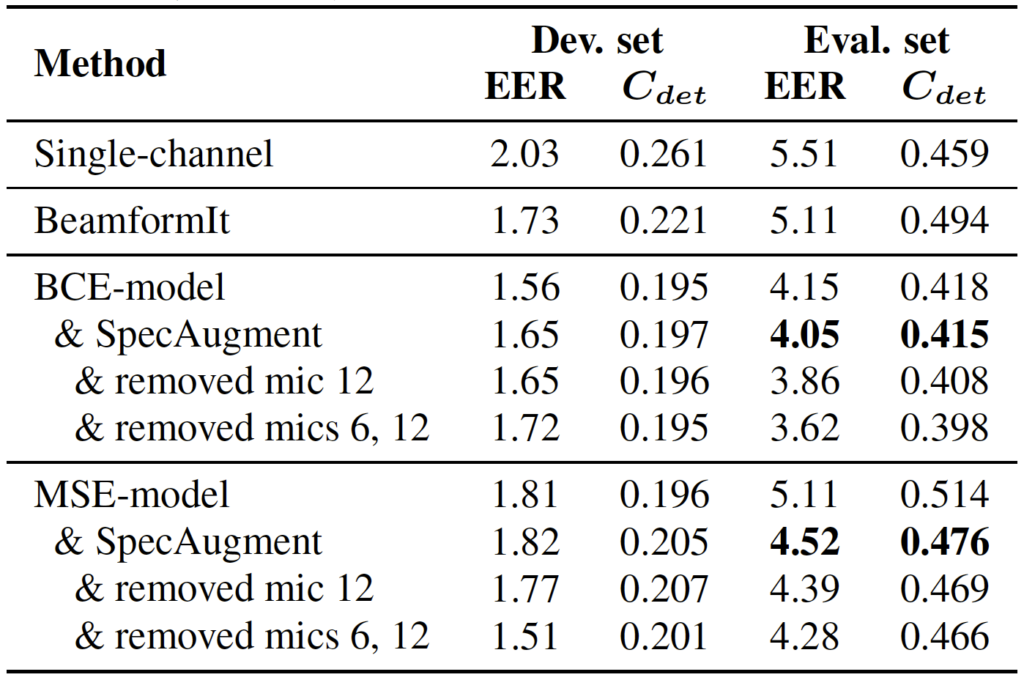
Table 3 summarizes the results of their experiments evaluated on the VOiCES data. Both of their models, BCE and MSE, outperform the single channel system as well as fixed beamformer baseline from BeamformIt. The results also indicate that the BCE model performs better than the MSE trained system, suggesting that the task of learning how to mask the noise from optimizing directly on the MSE of the outputs is more complex. Furthermore, the BCE model also seems to have generalized better, most likely due to the fact that the simulation procedure allows to train using a more varied set of conditions.
Finally, motivated by a desire to identify poorly performing microphones that can degrade the performance, the authors used a single channel x-vector extractor to do a per-mic study. They found a strong dependence on the distance between the microphones and the source, and identified two particularly poor channels: the worst (microphone 12) was placed on the wall and fully obstructed, and the second worst (microphone 6) is an omni-directional lavalier placed far from the source. In line with these studies, the authors removed these two channels from their evaluation and found a sizable improvement on the performance.
Speaker verification algorithms continue to improve due to advances in both the back and front-end of the system pipelines. In particular, the combination of traditional signal processing and modern deep learning techniques have proven extremely successful and delivered some of the more recent state-of-the-art implementations. It is exciting and rewarding to see in the papers we have discussed over these two blogposts, how the availability of a large corpus reflecting realistic acoustic environments can be leveraged to build robust systems that will perform accurately in extremely challenging conditions.
Helpful links
If you are interested in learning more about the VOiCES dataset, the Interspeech 2019 challenge or our upcoming VOiCES vol. 2 release we encourage you to either reach out, or follow any of the following helpful links:
- VOiCES: The final release: https://gab41.lab41.org/voices-the-final-release-f28d00a87395
- Interspeech 2019 VOiCES from a distance challenge: https://gab41.lab41.org/interspeech-2019-voices-from-a-distance-challenge-21ffd6ee5ef7
- VOiCES: Closing one chapter and starting a second: https://gab41.lab41.org/voices-closing-one-chapter-and-starting-a-second-1c67d32ac888
- VOiCES: SRI International and IQT Labs collaborate on advancing speech research for far-field application: https://medium.com/dish/voices-sri-international-and-iqt-labs-collaborate-on-advancing-speech-research-for-far-field-bbec59fccbe4
- VOiCES website: https://voices18.github.io/
- VOiCES took-kit repo: https://github.com/IQTLabs/VOiCES_Toolkit