

Where in the World, Part 1: A New Dataset for Cross-view Image Geolocalization

Cover image: CC BY Roberto Guido
Suppose that a photograph has surfaced on social media or through some other dubious origin, and you want to know: Where was it really taken? Let’s suppose it’s an outdoor photo, with enough background scenery that someone familiar with the place could identify the location. Or similarly, a location match could be made by comparing against other photos taken on the ground. Attempts to figure out the location of a photo this way soon run into a roadblock: For large swaths of the world, there simply isn’t an abundance of densely spaced, widely available photos to use as points of comparison. In such cases, satellite imagery provides a potential solution, because satellite images can be readily obtained for anywhere on earth.
With that in mind, IQT Labs conducted the Where in the World (WITW) project for the past year to develop tools and capabilities for cross-view image geolocalization (CVIG). CVIG is the process of matching a ground-level outdoor photograph to its location using overhead imagery of potential locations as the only point of reference. Overhead imagery refers to images captured by satellites, aircraft, or similar overhead sources. For a task of this scale and complexity, deep learning is an indispensable tool. Although there is a history of prior research on CVIG, too often it has focused on highly constrained datasets that do not reflect the difficulties of real-world use. Addressing these difficulties head-on was the primary focus of Where in the World. We developed a realistic new CVIG dataset, an open-source CVIG software repository, and insights into CVIG that will be presented in a three-part blog post series, of which this post is the first. Our dataset, using ground-level imagery from Flickr and satellite imagery from SpaceNet, addresses many of the limitations of previous datasets (Figure 1 shows example data). Although our dataset is not being publicly released, this discussion serves as a how-to for developing datasets along these lines. Our model uses state-of-the-art deep learning to automate CVIG. Using our model, we undertake experiments to demonstrate the capabilities and limitations of cross-view image geolocalization.


Figure 1: Example image pair from the WITW dataset. (a) A photograph from Flickr, taken in Moscow. License/credit: CC BY-SA Aleksandr Zykov. (b) A satellite image of the same location from SpaceNet.
Real-World Applications
When might it be necessary to find or verify the geographic location of a photo? Some compelling use cases can be found in the work of non-governmental organizations that manually employ cross-view image geolocalization for investigative or journalistic purposes.
One example is the investigative journalism collective Bellingcat. In one case, they were able to geolocate a photograph associated with a reported extrajudicial killing in Libya in 2018, by matching the buildings in the photo’s background to the same buildings as seen in overhead imagery. In another case, they verified the location of a video showing the aftermath of a reported chemical weapons attack in Syria that same year by matching a video frame to overhead imagery. Bellingcat has used CVIG in their investigations of Russian intervention in eastern Ukraine, the destruction of Uighur mosques in Xinjiang, and other occurrences.
Another example comes from the James Martin Center for Nonproliferation Studies (CNS). They looked at cases of North Korean state media documenting leaders’ visits to factories connected to the country’s missile program. Specifically, they investigated a dozen visits where state media conspicuously did not name the factory being visited. (Instead, each was obliquely referenced by the name of its manager.) CNS was able to identify the factory in question in every case, in part by using cross-view image geolocalization on the North Koreans’ own propaganda.
The work in these examples was done by hand. Even if automated approaches never became as capable as the human experts behind these efforts and others, merely having the ability to eliminate or prioritize candidate locations could make this type of work less tedious and more scalable.
Previous Work
The task of geolocating photographs (i.e., finding the geographic location captured in a photo) dates back many decades within the broader fields of photogrammetry and information retrieval. The specific approach of training neural networks to match photos with overhead imagery, however, is much more recent.
The first approaches to automatically matching photographs with overhead imagery used traditional machine learning and/or image processing techniques. In 2015, Lin et al. applied deep learning to the task. Their method, which has now become standard, was to use what’s now sometimes called a “twin network”: one convolutional neural network (CNN) maps photographs into an abstract feature space, and a second CNN maps overhead images into the same feature space. That same year, Workman et al. also explored the use of deep learning, introducing the original Cross-view USA (CVUSA) dataset. This dataset contains pairs of images: in each pair is a ground-level photograph and an overhead image centered on the location where the photograph was taken. Ground-level photos were drawn from Flickr and Google Street View, while overhead imagery was drawn from Bing Maps. A 2017 paper by the same group introduced an adapted and slimmed-down version of CVUSA using only Google Street View for ground-level photos. This would become the most widely used dataset for CVIG research. (Hereafter, all references to “CVUSA” will refer to this second version of the dataset.)
Subsequent years saw the publication of new datasets and new deep learning models for CVIG, often both in a single paper. Selected datasets include GT-CrossView and CVACT, both drawing from Google Street View and Google Maps. Many models introduced innovations into a basic twin network design. For example, Liu & Li used a twin network where input images were given extra bands to explicitly encode orientation information. Alternately, Shi et al. used a twin network with features associated with each orientation angle, so that the ground-level photograph could be matched to the most compatible viewing direction. At less than two years old, Shi et al. (from CVPR 2020) arguably represents the state of the art in CVIG. Other recent efforts have looked at novel acquisition methods (drones for the University-1652 dataset), novel analyses (such as using GANs), and novel data types (such as semantic maps in applications for self-driving cars).
Cross-view image geolocalization is closely related to the problem of geolocating a ground-level photograph by comparing it to other ground-level photographs (as opposed to overhead imagery). This related research area has its own extensive history, from early efforts preceding deep learning (like IM2GPS) to powerful deep learning techniques (such as PlaNet or Müller-Budack et al.).
Limitations of Existing Datasets
The past few years have seen rapid progress in the academic research of CVIG models. But there’s a catch: The most widely used datasets are not realistic representations of real-world use cases like those discussed two sections above. Here we discuss the limitations of previous datasets, and how the new Where in the World dataset addresses each one.
- Ground-level imagery: The most widely used datasets, including the ubiquitous CVUSA, use images from Google Street View or equivalent products for ground-level imagery. These images are very different from ordinary photographs that one might take with an ordinary camera or smartphone. Google Street View images are full 360-degree panoramas, with known orientation, known horizon line, and known angular size for every visible object. Regular photos are not nearly so well constrained. The WITW dataset uses regular photos.
- Overhead imagery: Most widely used datasets, including CVUSA, use overhead imagery from Google Earth or equivalent products. Such imagery is drawn from a mix of aerial and satellite sources, and it’s not always clear how a given image was collected. Because the WITW dataset is developed from the SpaceNet corpus, we know exactly which satellite collected each overhead image. (In fact, all of them are sourced from just two satellites: Maxar’s WorldView 2 and WorldView 3.) Knowledge of the collection mechanism and sensor allows us to minimize systemic errors that arise from uncertainty in topics such as resolution, observation angle, time of day, etc.
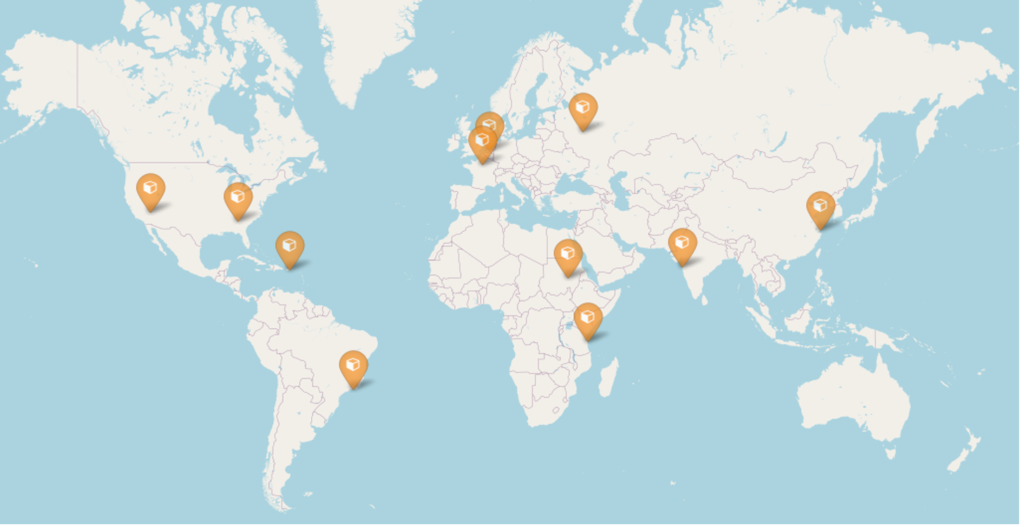
- Geographic diversity: Most CVIG datasets are limited to a single country, if not a single metro area. This limitation affects even those few existing datasets that use ordinary photographs from photo sharing sites. The WITW dataset, on the other hand, includes three U.S. and eight international cities, representing nine countries across five continents. Furthermore, the heavily urban focus of the WITW dataset makes it a useful counterpoint to CVUSA’s largely rural emphasis.
- Licensing: Some datasets include ambiguous licensing. For the WITW dataset, each image has an unambiguous open license, such as various Creative Commons licenses.
By making these improvements, and particularly by using ordinary photographs instead of precisely characterized panoramas, the result is a dataset that more accurately approximates real-world use cases for cross-view image geolocalization.
The Where in the World Dataset
The novel Where in the World dataset contains 164,455 pairs of images. Each pair consists of one geotagged photograph (i.e., a photograph of known latitude and longitude) along with a satellite image centered on that same latitude/longitude. Developing a dataset to achieve the goals in the previous section requires using the right data sources. For ground-level photos we drew from Flickr, a large and well-known photo sharing website. For overhead imagery, we used optical satellite imagery from SpaceNet. The discussion of how the dataset was developed begins with the satellite imagery:
Satellite Imagery from SpaceNet
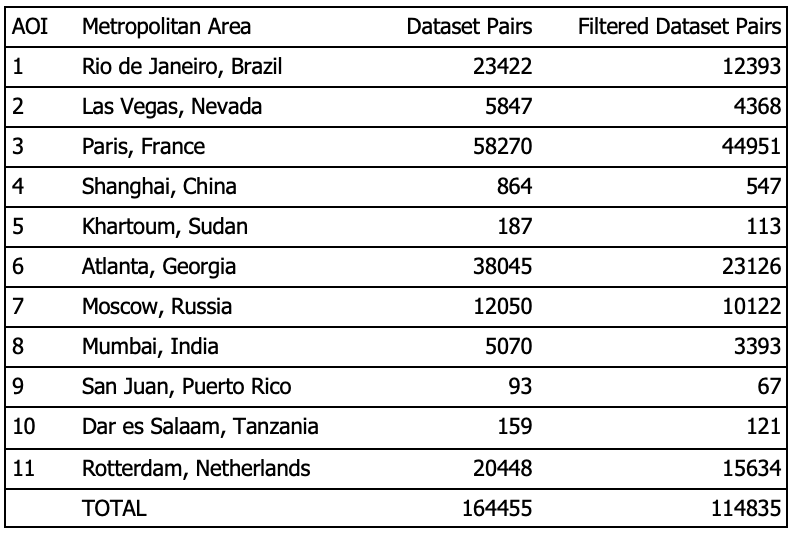
The SpaceNet corpus includes high-resolution optical satellite imagery from 11 areas of interest (AOIs), each of which is partially or fully located within a major city. Table 1 describes, and Figure 2 shows, the locations of these AOIs. By selecting only Flickr photos geotagged as being in one of these AOIs, we could then get the corresponding satellite views from SpaceNet.
A few data processing steps were required to prepare the SpaceNet imagery for use in the dataset and make the AOIs consistent with each other. First, each pan-sharpened image strip was converted from 16bit to 8bit color depth, with appropriate normalization. Most of the SpaceNet images contained more than three bands to accommodate various sensors on the satellite (some ranging into the infrared), so in the same step only bands corresponding to red, green, and blue were retained. This conversion was done with a utility from the CRESI software package.
After standardizing the images in terms of data format, the next step was to reproject them into appropriate coordinate systems. For each AOI, the local UTM coordinate system was used. A resolution of 0.3m was selected. For WorldView-3 images this was close to their original resolution; for WorldView-2 it represented a modest enlargement. The reprojection was done with the gdalwarp tool from the GDAL library.
At this point, squares of satellite imagery could be cut out centered on the geotag (reported location) of each Flickr photo. Imagery squares were chosen to be 750 pixels on a side, corresponding to 225m.
Ground-level Photographs from Flickr
For inclusion in the dataset, Flickr photos had to meet several criteria.
- They had to be photos that had been publicly shared by their owners.
- They had to be geotagged, and the geotag had to fall within one of the 11 AOIs for which satellite imagery was available. Geotags are often automatically added to a photo’s metadata by a GPS-enabled camera or smartphone taking the picture, although they can also be added/modified by hand.
- Images with a license of “All Rights Reserved” were excluded for copyright reasons.
To download the photos from Flickr, an API key was requested, to enable interaction with Flickr’s API from within Python scripts using the flickrapi package. API queries were used to collect URLs and metadata for photos meeting the above criteria, after which the images themselves could be downloaded. A Docker Compose approach was set up that could manage code dependencies and API keys. Because missing/redundant data can result from Flickr API queries that return too many results, we developed a script that first queried over large geographic areas then iteratively divided them as necessary to produce appropriately sized queries. Since Flickr provides a choice of image sizes, we selected a medium size of 500 pixels along the photo’s largest dimension to include sufficient detail without taking up unnecessary disk space.
One final criterion was applied only after the photos were downloaded. Cross-view image geolocalization is only effective for outdoor photographs, so it was necessary to exclude indoor photos (roughly half the downloads) from the dataset. To do that, we used the trained ResNet18 model released alongside the Places365 dataset. Among the properties predicted by that model is whether a photograph shows an indoor or outdoor scene.
Dataset Attributes
The 160,000+ image pairs of the WITW dataset take up 29 GB of space. The ground-level photographs are drawn from nearly 8,000 distinct Flickr accounts. Although the geographic spread of the cities ensures a certain geographic diversity, the cities themselves are not sampled with geographic uniformity. As an extreme example, the Paris AOI includes one of the most photographed sites in the world: the Eiffel Tower. A nearby bridge with an evidently scenic view is the location of more photographs than the entire city of Khartoum. The disparity between places with many available photos and places with few available photos is not surprising. Indeed, the limited supply of ground-level photos in some locations is the very problem that CVIG seeks to address.
Conclusion
By revealing the geographic origin of photographs, cross-view image geolocalization can help make sense of conflicting information – and disinformation – diffusing through our high-tech world. This challenging task has proven amenable to deep learning methods under certain circumstances. But testing these methods under real-world conditions requires a new kind of dataset. The WITW dataset fills a unique niche, due especially to its geographic diversity, focus on populous areas, and use of unconstrained photographs taken by thousands of photographers. In the next post in this series, we’ll put this novel dataset to use to train a new deep learning model.