


MIT Technology Review named Reinforcement Learning (RL) as one of its 10 Breakthrough Technologies in 2017. You may be wondering what it is given the wealth of discussion around Machine Learning (ML). RL is a subfield of ML emerging from academia that allows a system to make decisions without explicit programming. In this blog we explore the frameworks of an RL system and its applications, including cybersecurity, medicine, and autonomous vehicles. We encourage you to listen to the accompanying podcast discussing in greater detail to explore current and future uses of RL.
RL is a complementary ML paradigm that allows a model to autonomously evolve and make decisions to achieve a prescribed objective. In contrast to traditional ML approaches, RL directly addresses applications that require continuous decision-making under new and highly-uncertain conditions. The premise of RL is simple: if we can understand a system and predict its behavior, then we may be able to control it to achieve our own objectives. The various frameworks supporting RL are applicable to a broad range of human activities and present a powerful approach to automating complex processes like logistics and planning, autonomous vehicles, and human-computer interaction.
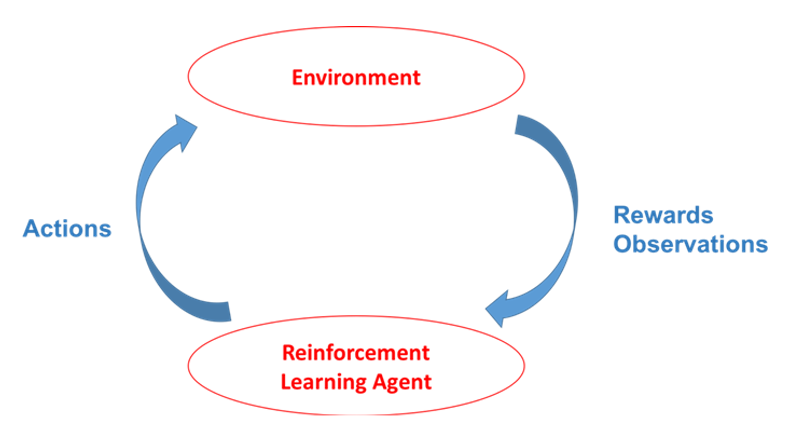
While RL systems have yet to demonstrate the sophistication of general human decision-making abilities, some have achieved extremely promising levels of aptitude in well-structured problems. The outstanding challenge of applying RL lies in translating real-world problems into the requisite mathematical framework. The basic framework for RL involves three elements that encompass the decision-making cycle:
- Observe a context: information that defines the states in which the RL agent exists;
- Execute an action: this may be a single, predefined operation, like choosing a restaurant, or more complicated orchestration, such as tuning an array of industrial controls; and
- Observe a reward: a quantifiable metric that defines the optimality of each action taken in any particular context.
An RL model is often instantiated within a particular domain. This limits the available contexts to a manageable set, described by a number of predefined environmental variables, or features. Within each context, a number of actions are also available to the RL agent. These include finite action sets, such as choosing from a collection of news articles. It also includes continuous, multi-dimensional action spaces, for example those used in operating multi-rotor aircraft. Most importantly, the model must be given an end goal defined by an objective function, which is simply a mathematical expression that describes the reward received by taking a sequence of actions. The application domain also dictates the objective in many cases.
As time and other operational resources play a crucial role in the learning process, objectives must be limited in scope to a relatively small number of quantities that are observable within a reasonable period of time. For example, a video recommendation engine based on RL might define specific user characteristics such as age, geographic location, and gender as features that describe the context, and a collection of videos to display as the set of possible actions. An objective, or reward, may be received if a user clicks on a recommended video. Initially, the model has very little idea which videos to recommend to different users. However, over time, the RL algorithm gains a better understanding of the effects of its actions by exploring different items to recommend in different contexts. This captures some of the key differences between RL and traditional ML techniques. The RL agent is constantly provoking and receiving feedback from the environment, with the goal of discovering actions that maximize rewards. Internally, all experiential information is embedded in the model to inform future decisions as new situations appear. This creates a continuous learning process that is adaptable to new situations or dynamic environments. Further, many unsupervised and supervised learning techniques are components of RL algorithms, assisting in accurate prediction and representation of new information.
It is important to note that passive learning algorithms do not prohibit effective decision-making. In fact, supervised models like decision trees are highly effective in applications that have been fully explored and do not change over time. The primary advantage of RL models is their ability to operate in uncertain environments in which the eventual reward of taking a sequence of actions is unknown. Autonomous exploration is therefore an integral component of RL frameworks and critically influences model performance. Through exploration, the model may improve itself in a systematic way and efficiently gather information necessary to operate more effectively.
Operating in uncertain environments presents a number of practical challenges aside from the overarching issue of problem specification. RL models are typically constrained by the resources that allow them to collect new data and take particular actions. Computing and storage are required for model execution, but data acquisition, processing, and autonomous exploration may be incredibly costly as well. As an extreme example, consider the cost of obtaining core samples to evaluate new locations of valuable mineral deposits. Here, the decision problem is relatively simple since the reward from assessing a new location is immediately realized. But often, a course of action will involve multiple actions taken in sequence. As the decision space becomes more complex, the RL model often requires more time to explore different options.
Exploration, in turn, entails greater time and operational costs which may prohibitively detract from the value of discovering an optimal strategy. To address this contingency, RL models rely heavily on the so-called exploration-exploitation tradeoff to deliver the most beneficial strategy as quickly as possible. Faced with a multitude of potential strategies, an agent must constantly decide whether to simply explore the search space, or exploit what is has learned to deliver the greatest near-term reward. Additionally, to prevent the model from endlessly exploring different possibilities, the rewards may be discounted based on the amount of time taken to reach them. This strongly incentivizes simpler strategies with fewer sequential actions.
The Utility of RL
You’re likely to be aware of the most notable accomplishment of RL — its success in the classic board game Go. The RL system, Alpha Go9, was used by Google DeepMind to defeat the world champion of Go in 2016. The complexity of learning optimal strategies in Go led many experts to dismiss the possibility of machines besting human players in the near future. However, using a combination of Q-learning and stochastic tree search, alongside large amounts of self-directed, experiential data, Alpha Go not only demonstrated the power of RL, but provided a foundation for a wide range of similar applications. Recent advances in deep neural network models were also instrumental in extending Q-learning to real-world applications.
Autonomous Vehicles
Robotics have historically been the most common application of RL, primarily because they are easily programmable and provide a clear context for relating actions to rewards in the RL setting. RL approaches have been applied widely to autonomous vehicles, such as drones and self-driving cars, to enable high performance and adaptive systems that can navigate and recognize environmental features with near-human ability. Experiential data is often expensive to acquire, particularly in settings where a physical vehicle must be deployed with a full array of control and sensor components. However, swarms of such vehicles may be used to simultaneously collect information to construct a global RL model, significantly reducing the time required to find acceptable policies for a vast range of real-world contexts. At this time, RL is not independently sufficient to direct such vehicles in all real-world situations, as a number of external factors also contribute to decision- making, including liability, cost-benefit tradeoffs, risk analysis, etc. However, the RL framework provides a proficient means of building control systems to conform to complex environments and becomes a powerful operating component when used in conjunction with traditional control mechanisms.
Chat Bots
Human-computer interaction via text has emerged as a hugely impactful technology, bridging the gap between natural human language and computational systems. Applications largely focus on integrating basic language capabilities into application interfaces of commercial products and service industry. A major challenge for these systems is to understand complex dialogue and respond appropriately. The situation is exacerbated when chat systems must switch between different industries, user demographics and media. In many ways, the process of tuning responses resembles a RL problem, where the user responds favorably to the system if it behaves correctly. Take Apple’s Siri: if a user is forced to repeat a question multiple times, the system should receive a negative or null reward, while if the response completes the interaction, the system should be rewarded positively. On the other hand, RL systems are incredibly sensitive to their training environments, and when placed in an uncontrolled situation, may respond unexpectedly, or become vulnerable to manipulation. Microsoft’s chat bot experiment, named Tay, is a prime example of a system learning disastrous behavior based on exposure to a small and malicious subset of training examples. Training such systems using RL is still in its infancy, but with the wealth of voice and text data available through mobile applications, RL is quickly becoming a viable approach.
Virtual Agents
Simulations and video games often implement virtual agents to model autonomous behavior or provide an adversary for a human player. Until recently, such entities were implemented using either deterministic (rule-based) or quasi-stochastic behavior models. However, recent advances in RL have motivated an experiential learning approach to teach virtual agents to behave and respond to human players and other virtual entities. Such agents can learn complex behavior and become integrated elements of their own environments. These applications open up a number of possibilities in human simulation and social dynamics, where the complex interactions between human beings have confounded traditional behavior models.
Cybersecurity
Detection of network intrusions has remained a challenging and often elusive goal for system administrators and IT personnel. Many approaches that rely on rule-based techniques, or probabilistic inference, are limited in their ability to evolve and detect new types of attacks or identify optimal mitigation strategies in retrospect. The RL paradigm is highly amenable to this type of situation, and novel detection approaches introduce RL elements into existing detection systems to contend with new threats as they arise, or use the wealth of network infrastructure to develop superior prevention policies.
Medicine
Often cited as the new frontier for artificial intelligence, medical diagnostics and treatment have a great deal to gain from novel machine learning approaches based on empirical evidence. Especially when multiple lines of treatment are involved, the outcome for a specific patient can be very hard to predict. RL has potential to reveal complicated, individualized treatment regimens and diagnostics that augment existing clinical strategies.
The majority of approaches and implementations of RL systems are highly experimental and continue to evolve quickly. This blog outlined the most mature techniques and applications, with ready-soon commercial applications.
References
1. L. G. Valiant, Comm. of the ACM, 27 11 (1984)
2. R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction. MIT Press (1998)
3. D. R. Jones, M. Schonlau, W. J. Welch, J. Global Optimization, 13 (1998), C. E. Rasmussen, C. K. I. Williams, Gaussian Processes for Machine Learning. MIT Press (2006)
4. M. N. Katehakis, A. F. Veinott, Mathematics of Op. Res. 12 2 (1987)
5. V. Kuleshov, D. Precup, JMLR 1 (2000)
6. N. Srinivas, A. Krause, S. Kakade, M. Seeger, ICML (2010)
7. D. Bertsekas, Dynamic Programming and Optimal Control 2 Athena (1995)
8. L. P. Kaelbling, M. L. Littman, A. W. Moore, JAIR 4 (1996)
9. D. Silver, et al., Nature 529 (2016)