

Transfer Learning for Classification in Ultra-small Biomedical Datasets
Image credit: public domain — provided by the National Cancer Institute
Do you see cancer in the mammogram above? If you’re struggling, don’t worry, you’re not alone. Biomedical imagery is a domain where computer vision and artificial intelligence could be better suited to outperform human judgement. A recent Google study that used over 25,000 medical images supports this claim; they were able to build a machine learning model for breast cancer detection that outperformed humans, presumably, in part, because breast cancer detection is difficult, even for trained professionals. Machines often excel at these texture-based challenges. (In case you are curious, there’s no cancer in that mammogram.)
But before computer vision can broadly assist in evaluating biomedical imagery, there’s a data problem to solve: many possible biomedical applications have access to only a few hundred labeled images. If machine learning researchers have only hundreds, and not tens of thousands, of biomedical images, can a useful, predictive tool still be built?
In this series of posts, we will empirically explore some of the options and tools that data scientists can use when working on extremely small biomedical imagery datasets. Our focus will be on classification tasks that do not require segmentation; for example, these datasets could be for identifying if there is a tumor in a brain scan, not where the tumor is in the brain scan. This series will explore questions such as:
- How applicable is transfer learning from existing, general-purpose models? Do ImageNet models (trained to distinguish between a thousand classes of things like cats and dogs) help us detect differences in cell-based photographs?
- If not, can we build a general-purpose “CellNet” model that can be used successfully for transfer learning for cell-based biomedical images?
- What kind of data augmentation and pre-processing works for this biomedical domain?
- What other approaches, such as dataset purification or using only high-confidence predictions for image triage, could we employ to make these models, built off ultra-small images, more usable in real-world settings?
Does Transfer Learning Work for Ultra-small Biomedical Datasets?
In this first post, we’re going to tackle the common problem of limited training data by examining how, when, and why ImageNet-basedtransfer learning can be used effectively (or not). Transfer learning refers to the idea that a large, pre-trained model can be reused on a new dataset, recycling the learned parameters and their weights for a new classification task. For example, you can download a model that was pre-trained on millions of images from ImageNet to predict common objects. Then you can replace its final layer to predict, for example, four different types of white blood cells, instead of birds or cars.
These pre-trained models have learned to recognize lower-level features like straight lines versus curves, which could help distinguish the outlines of a cat’s whiskers from a dog’s snout. With transfer learning, these simple features can then be recycled when trying to differentiate different blood cell types, obviating the need for thousands of blood cell images and countless hours of model retraining. That’s the theory at least.

How well transfer learning works depends, in part, on the similarity between a dataset and ImageNet, above (assuming you’re using a model built off of ImageNet, like pre-trained vgg or ResNet). On one hand, transfer learning seems to work well for many biomedical applications. On the other hand, it often doesn’t. Recent work out of NeurIPS by Raghu and colleagues from Cornell and GoogleBrain hypothesized that rather than using transfer learning from an entire general-purpose, large-scale model built off ImageNet, data scientists may be better off recycling only the lower layers of these pre-trained models. The upper layers of the model can then be simplified and locally trained. By recycling lower-level features, one would expect to get the benefits of training a model to recognize shallow features like lines and curves, which may be especially important given the fine-level detail found in biomedical imagery. We’ll evaluate that approach with our datasets here.
Ultra-small Biomedical Datasets: the Good, the Bad, and the Ugly
To investigate the feasibility of transfer learning for ultra-small biomedical image datasets, we set up experiments to classify open-source benchmark imagery, using pre-trained vgg16, ResNet18, and two custom-designed Convolutional Neural Network (CNN) architectures. Below are examples from our nine biomedical, mostly cell-based datasets we used to benchmark different models. We provide further details and results for each benchmark in the sections below.
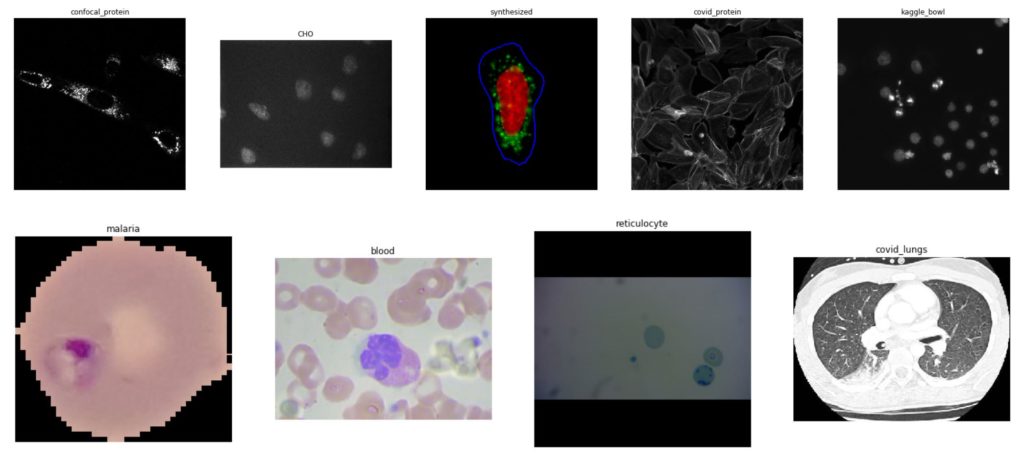
For all benchmarks, we did our best to ensure that our models learn what we want them to learn (a cell shape, for example) and not circumstantial artifacts (like a background color). Given the limited size of our datasets, we applied basic data augmentation during training: flipping, rotating, normalizing, and color jittering each image to try to help with generalization. Because classes were often imbalanced, we balanced classes during training through a WeightedRandomSampler passed to the DataLoader. In a future post, we will explore in detail how data pre-processing affects these types of models.
Images were either cropped or resized, depending on which was feasibility and performance so that each image conformed to the 224×224 base of ImageNet. Notably, we fed these resized images into our custom CNNs, and it remains an open question whether other bespoke CNNs built on non-resized images could work better. (We will explore in later posts.) Our entire experimentation source code is available on git, while the images can be downloaded from their original sources linked in the sections below.
Full and Partial Transfer Learning versus CNNs from Scratch
We sought to answer the following questions as we investigated how transfer learning could be used to build predictive models on these small but relatively homogenous datasets:
- Is ImageNet-based transfer learning better for this type of data than a CNN built from scratch?
- Is reusing only lower layers of a pre-trained model, as some researchers suggest for this domain, more effective?
- How fragile are individual models built using subsets of training data during cross-validation? Should we employ a voting ensemble method due to our ultra-small datasets?
To answer these questions, we used pre-trained vgg16 and ResNet18, and two CNNs built from scratch (without pre-training on ImageNet) to set up the following experimental models:
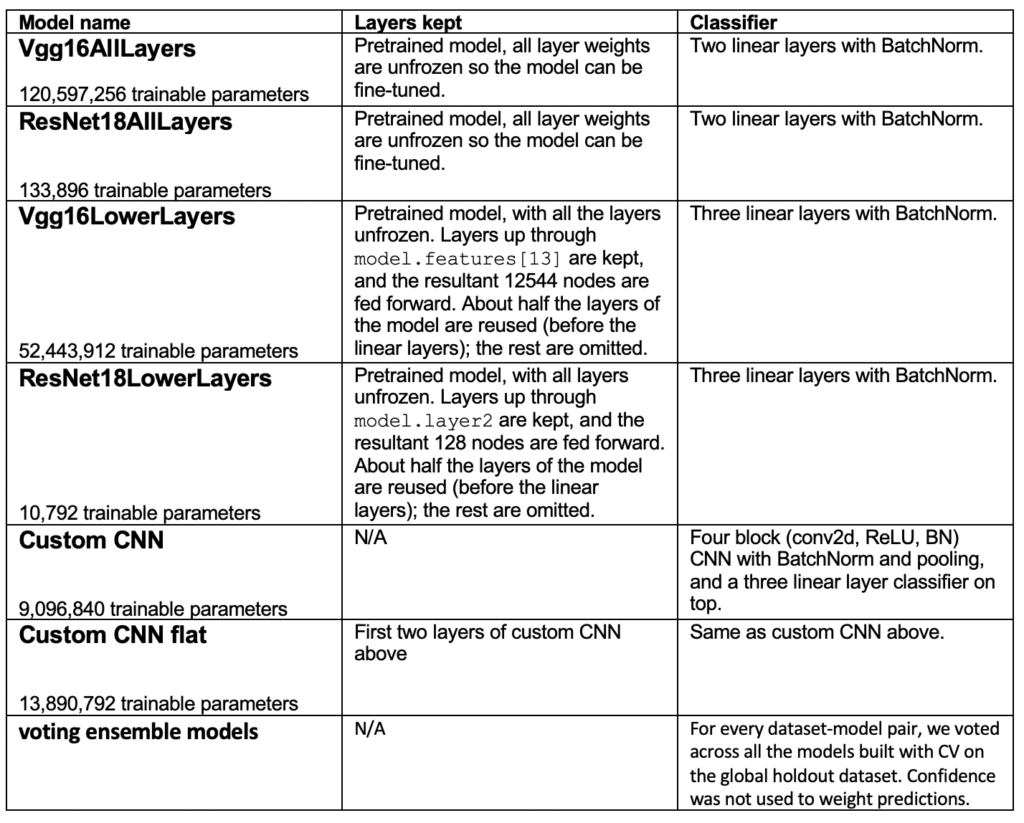
For each dataset, we kept a global holdout of 10% of the entire dataset to compare performance across the models above. The remaining data was used for 5-fold cross-validation, repeated four times, giving us 20 models for each dataset-model pair. We then calculated the average weighted accuracy across all 20 models on both the holdout test set and a local test set used in each cross-validation. When training the models, we used the same batch size (32), while we calculated a reasonable learning rate and epochs for each benchmark to allow all models to finish learning, but not take too long to run 20 trials for each of the six architectures per benchmark. Typically, this was around 20–30 epochs and a learning rate of 1e-3, unless otherwise noted below. We did not freeze the layers of the models.
We also used a voting ensemble model that combined the predictions across all twenty models on the holdout test sets. Notably, we didn’t expect these models to perform well out-of-the-box on our benchmarks; our goal was to make basic comparisons. For a data scientist trying to build an effective model for a specific dataset, they would devote significant time to optimizing such models. These experiments are meant to be used as a broad guideline for future experiments related to small biomedical datasets.
Cell Shape Detection and Transfer Learning
Several of our datasets involved classifying what cell type (or shape) a culture slide belonged to; these are common idioms and tasks in the biomedical domain, whether used for classifying proteins, or sub-cellular structures. Learning to identify these types of low-level textures and patterns is fundamental in the biomedical classification domain; however, it’s unclear how much overlap there is between these features, and what ImageNet-based models are prepared to transfer.
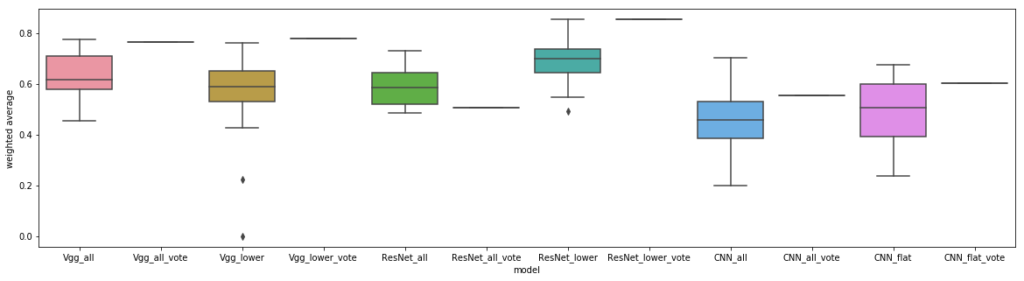
Therefore, we trialed our two ImageNet-based models (vgg16 and ResNet18), both in full and only using their lower layers, against two CNN models (a deeper versus a more shallow one) without transfer learning; a discussion of the results is presented for each dataset below. To reduce cognitive load, we’re only showing the results on the holdout test set for each benchmark, which was almost always in line with the observations for each model’s test set performance during its cross-validation trials. We also show the voting ensemble model performance on each holdout, where each of the 20 models trained through cross-validation vote on the classification.
We first tested transfer learning on a sub-celluar protein classification challenge. From the perspective of a computer vision model, we can imagine this problem as trying to distinguish between different patterns of cell shapes:

In this dataset, we resized these 1024×1024 pixel images to be 224×224 (to avoid cropping out salient structures), applied the basic transformations mentioned earlier, and trained the five models above, using each of the 20 models generated during cross-validation to create a voting ensemble model. Notably, transfer learning from ImageNet seemed to help here, although there wasn’t a large difference between using the whole architecture, versus only the lower layers.
The same setup was used for another dataset for classifying sub-cellular structures in 1024×1024 pixel images, with similar trends:
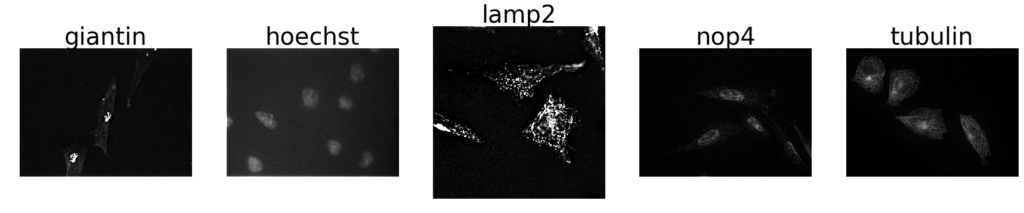
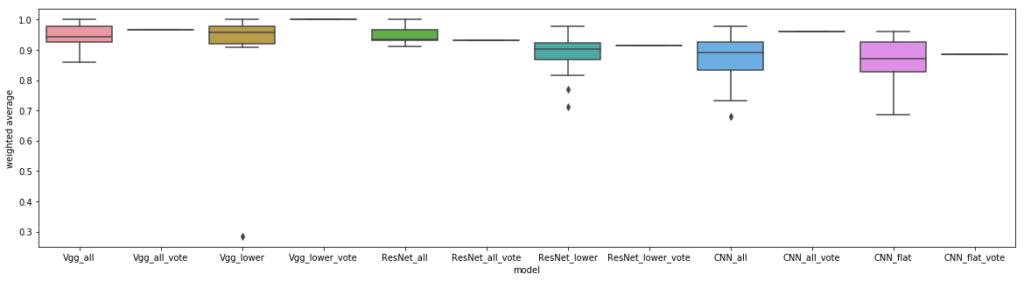
However, in this experiment, all transfer learning models approach near-perfect performance, especially with voting, presumably because there are fewer classes, with more images per class available to train on. This problem seems trivial even for untrained humans, and machines also easily learn these differences, although the general caveat of witnessing such high performance on such a small dataset always leaves the nagging question about model generalization.
Moving on to another sub-cellular protein classification dataset, we trialed our models against similar protein staining as on the images above, this time on epithelial cells from a small, random subset of a COVID-19 dataset of 1024×1024 pixel images:
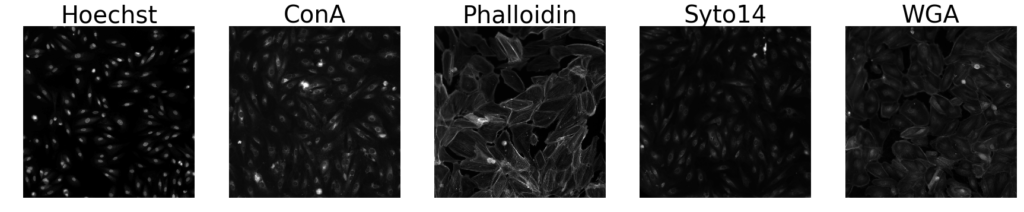
We resized the 1024×1024 pixel images to 224×224, rather than cropping them, because the former yielded better results; we also trained for only 10 epochs with a learning rate of 1e-4. This dataset is also something that’s easy for untrained humans to classify correctly, therefore it’s not surprising that the models above performed so well, especially because they had hundreds of images to train each class on:
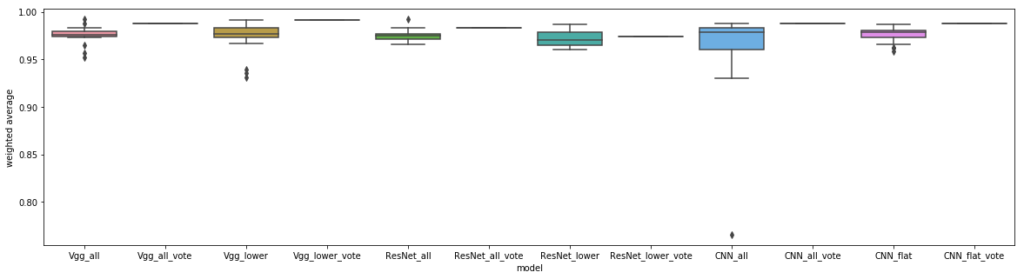
All the models performed quite well, hinting that the combination of task and number of images per class has reached a point of saturation.
How about another cell shape challenge, with many classes but few images per class? We predict that the task of classifying different cell shapes we manually annotated from a Kaggle data science bowl will perform similar to our first benchmark, with some lift from transfer learning. Even though the shape labels in this dataset aren’t biologically relevant, there are other applications where data scientists try to build models to differentiate cell shape and/or contents. These images varied widely in size, between 1024×1024 to 256×256 pixels, so we chose to greyscale and resize them to 224×224, as resized images are more likely to end up having closer cell sizes (making it more interesting to try to classify them based on cell shape):

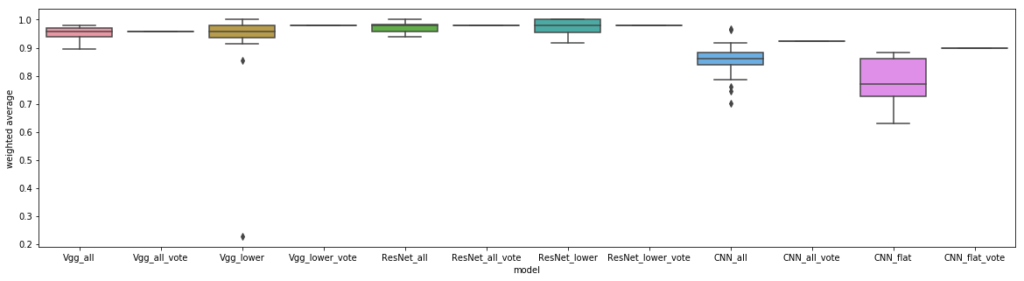
Transfer learning appears to be beneficial on this dataset, along with surprisingly good performance, given the limited class sizes. Why? One of the differences between this dataset and others we’ve seen so far is that we manually labelled these images by assigning a shape that came from different instruments and datasets originally in the Kaggle bowl competition; our task here was to identify cell shapes, but these Kaggle images were originally meant for nucleus segmentation. Therefore, one possibility is that our models were picking up on background noise that happened to be accidentally correlated with the cell shape due to the original image collection. Another theory is that the differences between the classes here are more subtle than the previous two obvious datasets, and perhaps transfer learning is particularly suited to teasing them apart.
Transfer learning for cell shape detection in cell cultures
Overall, we learned that for this type of cell-shape-based classification that transfer learning with either ImageNet-based model (vgg or ResNet) outperformed other CNN-based approaches. Part of the reason transfer learning works well for these problems may be that identifying different cell shapes on a slide of multiple cells is similar to identifying different textures. This is something that ImageNet-based models arethought to be good at, and perhaps we’re able to recycle their lower-level features in these experiments. We also observed the power of voting ensemble methods to out-pace the prediction accuracy of any individual model. In fact, a voting algorithm seemed necessary when using a model built with only lower layers of the original vgg or ResNet architecture, due to variance in individual model performance.
In our next blog post, we’ll continue this set of experiments on pre-segmented cells, as well as other types of biomedical datasets. We hypothesize that transfer learning from ImageNet may be less useful under these circumstances, given that these newer datasets might be more difficult to translate into texture challenges for our models. Stay tuned to see if these conclusions hold on other types of biomedical datasets, next!
Thanks to my colleagues Felipe Mejia, John Speed Meyers, and Vishal Sandesara
Thank you to the Murphy Lab for making available many of the datasets used here. For further information, see their paper: X. Chen, M. Velliste, S. Weinstein, J.W. Jarvik and R.F. Murphy (2003). Location proteomics — Building subcellular location trees from high resolution 3D fluorescence microscope images of randomly-tagged proteins. Proc. SPIE 4962: 298–306.