

What Smart Sensors Can’t See: Imperfections in the Dataset!

If you have ever uttered “Hey, Google” or “Alexa” to a virtual assistant, you have used a “wake word.” Even when a device is sleeping, special processors listen for specific audio cues so that the device can power on, or “wake up.” Google recently built on the wake words idea by introducing Visual Wake Words, extending the concept to visual cues. They propose using a low-power camera and processor to watch for specific objects and waking up a system when detected. This capability could create, for instance, a smart ceiling light that turns on when a person approaches or a pet door that opens only for cats. Google demonstrates the potential of this approach in a paper that shows it is possible to accurately detect a person on a device with limited power and memory. While the paper investigates the optimal parameters for building an effective person detection model, it states that the same method will allow for models to be trained to accurately detect other types of objects. This post provides an overview of our findings and then details the investigation we undertook. Our hope is that it will provide the motivation and techniques for researchers to better understand how to build models for visual sensors.
Before we go on, let’s pause for a minute and acknowledge how amazing it is that you can get a $15 device that is powered by a watch battery and can detect humans using a camera. Isn’t the future grand?
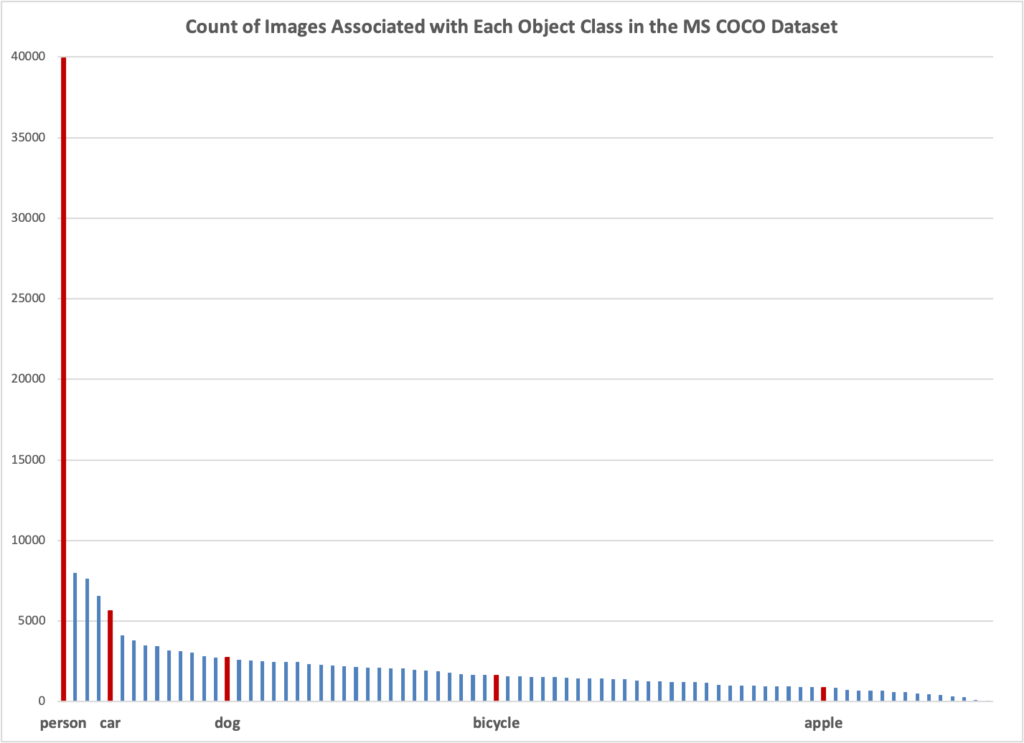
We started our work with the open source tools Google released to create Visual Wake Words datasets. The Visual Wake Words technique uses Common Objects in Context (COCO), a curated dataset of labeled objects found in images from the internet photography site Flickr, to train models. Google’s paper focused on detecting a person, which is the best represented object in the COCO data. Persons are present in nearly half of the 82,783 images being used from the COCO dataset. The next most represented class of objects, dining table, was present in less than 10% of the images. As you can see from the chart in Figure 1, representation only declines from there. With fewer images available for training, we assumed that the models generated for other objects would not be as accurate at detecting those objects.
After some initial work, we found that, despite our initial skepticism, the Visual Wake Words technique was able to build models that can accurately detect models even when there are a limited number of images to use for training. For instance, when training a model to detect apples, one of the rarest classes in the COCO dataset, a model can achieve a detection accuracy of over 99%. We found this initial detection accuracy by using a standard approach in machine learning of setting aside a portion of the training dataset to evaluate the model against. These initial results can be deceiving, as we learned when we began applying the model in the real world. This initial evaluation only describes the performance against the types of images in the dataset and if there is not enough variation in the dataset to reflect the real world, this evaluation does not accurately predict performance.
As we started to use the models to detect objects in the real world, we found that they did not always work as predicted. While the COCO dataset is made up of curated photographs taken by a human, the images captured by the smart devices we are targeting can differ in a number of ways. Smart devices that rely on Visual Wake Words techniques for their computer vision intelligence are often deployed from unusual perspectives, e.g., recall the camera in the ceiling fixture. These unusual angles could degrade model performance. Finally, smart devices also capture pictures continuously and capture many ill-composed images, which could further hurt model performance. In short, the images captured by smart devices might be very different from the COCO dataset, which is made up of well-composed photographs taken from the perspective of a photographer.
Figure 1. Count of Images Associated with Each Object Class in the MS COCO Dataset
In sum, an image is more than what is in the frame. Engineers building computer vision systems should keep in mind that COCO, like many computer vision datasets, are harvested from the internet. These internet-based image datasets are mostly taken by photographers and, consequently, have consistent human-height perspective and are well composed. To discover this blind spot, engineers can deploy the models interactively, methodically exploring the real world with the camera a running model, to create a short feedback loop. Additionally, traditional approaches to evaluating machine learning models—measuring only aggregate model performance and reserving a segment of the original dataset for evaluation—will reliably lead to real world failure. Finding and exploring these failure modes, based in part on hunches and intuition, should be a fundamental component of building systems with machine learning. The rest of this blog post walks through our investigation, detailing the steps we took.
In the Lab: Comparing Detection Performance for Persons to Other Categories
Google’s Visual Wake Words paper proposes a technique for detecting objects and then investigates using this technique to detect people. The authors found that using a MobileNet V1 deep learning model architecture allows for models that are small enough to fit the memory constraints of common microcontrollers while still being accurate enough for most tasks. While the paper asserts that the approach proposed will work for other types of objects, this is not investigated. Nor does the paper look at performance in the real world. To begin to assess this, we decided to run our own analytical experiments. Using the recommended MobileNet V1 model architecture, a model specifically tuned for compute-constrained edge devices, we compared the model accuracy across different object categories. This evaluation was done using randomly selected images from the COCO dataset that were set aside for this purpose. See Figure 2 for results by object class.
Figure 2: Accuracy of Model by Class Category
| Categories | Accuracy | Total # of Images in COCO |
| Apple | 99.2% | 858 |
| Bicycle | 98.1% | 1,605 |
| Car | 94.1% | 5,629 |
| Person | 84% | 39,926 |
To our surprise, model performance did not degrade when we used this data to detect other categories, which had far fewer images to train on. In fact, model performance actually increased! (We’re not sure why, though it could be because of the high variability of human activity.) Of course, this analysis only used a single run of the these models, so these findings are not statistically significant, only suggestive.
Getting Real: Model Performance Experiment #1 Outside the Lab
We first investigated car detection in the real world because of the potentially useful commercial applications of car detection. We collected images from an urban environment with a relatively inexpensive microcontroller development board (Arduino Nano 33 BLE Sense) and camera (Arducam Mini 2MP Plus) and tested how well the model detected cars. Because this camera, like the camera in many embedded systems, has relatively low-quality optical systems and image sensors, this task potentially poses a challenge to computer vision models usually deployed in a more pristine environment.
We collected 199 images, including 120 images with a car fully present in the image. All other images had no cars present. Much like the photographs in the COCO dataset, these images were captured from the perspective of a photographer and were intentionally composed. Following the Google paper mentioned above, we selected the MobileNet V1 architecture, which supports a range of image resolutions, as well as the use of color and grayscale images. We investigated the lowest resolution supported, 96×96 pixels, using grayscale images. This should be the worst possible combination. We also looked at color images with 128×128 resolution to see how much of an improvement there would be. The images were downscaled and center cropped to replicate typical image preprocessing. Figure 3 displays the results.
Figure 3: “Real World” Evaluation of Car Detection
| Color or Grayscale | Picture Size | Accuracy | Precision | Recall | Count of Pictures |
| Grayscale | 96×96 | 88% | 98% | 82% | 199 |
| Color | 128×128 | 91% | 98% | 87% | 199 |
Despite our skepticism, these real-world model results—results from using an actual on-board camera system—closely matched the “lab” results. We were also surprised to see that the model trained on lower-resolution grayscale images performed similarly to the model trained on higher-resolution color images. However, we came to realize that this data only reflects the overall performance of using the actual camera, not the image composition that a smart device deployed to an unusual angle might experience in the real world.
The Real World: Model Performance Experiment #2 Outside the Lab
Armed with a model possessing a 90% accuracy rate, we took to the city streets with a camera in hand and a model on-board the camera capable of detecting cars. We systematically circled cars with the camera, capturing multiple views of the same car. Despite the high accuracy score of the model, we discovered a common failure mode. The Visual Wake Words-trained model struggled with cars in images captured 30 degrees off center of the car’s front or rear. The model also fared poorly when presenting it with only the rear of a car. On the other hand, the model excelled at detecting cars when shown only a side view. See Figure 4 for an example of our circle-the-car analysis.
Figure 4: A “Circle-the-Car” Analysis of Model Deficiencies

We discovered a similar phenomenon when analyzing models trained on the Visual Wake Words dataset to detect bicycles. The model results appear sensitive to the camera’s perspective. These models handily detect bikes from a side angle with the perspective of an adult human. Tilting the camera towards the front or rear of the bicycle, or placing the camera higher up, notably decreased model accuracy. To confirm this observation, we created a dataset of images of different bicycles taken from multiple perspectives. Poor model performance against this real-world dataset matched our intuition.
What potentially explains this deficiency? Our hypothesis stems from the collection mechanism of the COCO dataset, the dataset that underlies Visual Wake Words. COCO images were collected for Flickr, a popular photo-sharing site. These images were taken by photographers and often intentionally composed. The dataset therefore reflects how a human may photograph objects in different scenes, allowing the training of accurate models for use with photographs taken by humans. But images captured by sensors, not necessarily taken at human height and not from typical photograph angles, are more heterogenous and potentially difficult for models trained on COCO.
From Awakening to (a Partial) Enlightenment
What began as a workshop experiment—can we get this newfangled Visual Wake Words model to work on a microcontroller?—transformed into a (still-in-progress) science experiment. We found that, yes, these Visual Wake Words-based models can work – at least sometimes – in the lab and in the real world. But these models have predictable blind spots. Because the COCO data is derived from internet photographs taken by people, these models do not perform well from non-standard angles: the types of angles that a remote camera, not operated by a person, might capture. This blind spot is similar to how the performance of computer vision models trained on satellite imagery depends on the satellite’s observation angle. We found these blind spots by deploying a machine learning model on a camera that we carried through a city, gathering real-time intuition about the capabilities and the limits of the model. But we don’t want readers to be discouraged. Visual wake words models are powerful—and by understanding their weaknesses—we believe this approach will soon be widely deployed in the real world.
We have published a GitHub repository with the Jupyter Notebook we used to build and evaluate the different models.
We thank Kinga Dobolyi and Adam Van Etten for a thorough and helpful critique.