

Privacy and Data Science: Protecting Sensitive Data in the Age of Analytics
As data privacy technologies mature, how do you choose the right one? Here is an overview of the promising partial-trust technologies.
Three Technologies to Protect Your Data Goldmine
According to the IBM/Ponemon “2019 Cost of a Data Breach Report,” there is more than a 25% probability an organization will have a material data breach within the next year. For consumers who are becoming increasingly concerned about the privacy of their online data, a 25% chance of a data breach is too high.
To protect customers’ privacy, organizations need to think about customer data differently. They need technologies that enable data science applications while protecting data privacy. Three of these technologies, discussed below, are differential privacy, homomorphic encryption, and federated machine learning.
The Limitations of Full Trust
The challenge is that while learning and data science are critical enablers of efficiency and effectiveness in modern organizations, taking advantage of them often means entrusting sensitive data to external vendors.
The prevailing privacy model tends to be binary: either the data science as a service provider has the organization’s full trust and gets direct access to the data, or they don’t have the trust and they get no access at all.
This “full trust” model creates an either/or situation that puts organizations in a difficult position of having to choose security or innovation.
Fortunately, there are several promising data privacy technologies that can ease that tension. These are “partial-trust” models that provide more room for both security and innovation.
Disambiguating Data Privacy Technologies
Data privacy is a new area. As a result, it can be difficult to differentiate between technologies. For example, all the below technologies “protect data” and “provide privacy.” Yet the technologies and use cases differ significantly. In fact, these technologies may be complimentary rather than competitive.
It is helpful to think of data privacy and related technologies through the lens of the “threat model.” What does authorized or unauthorized access look like? And against who/what are you protecting the data?
Differential Privacy
Differential privacy has seen major growth in the last few years, with major tech companies and even the U.S. Census Bureau adopting it.
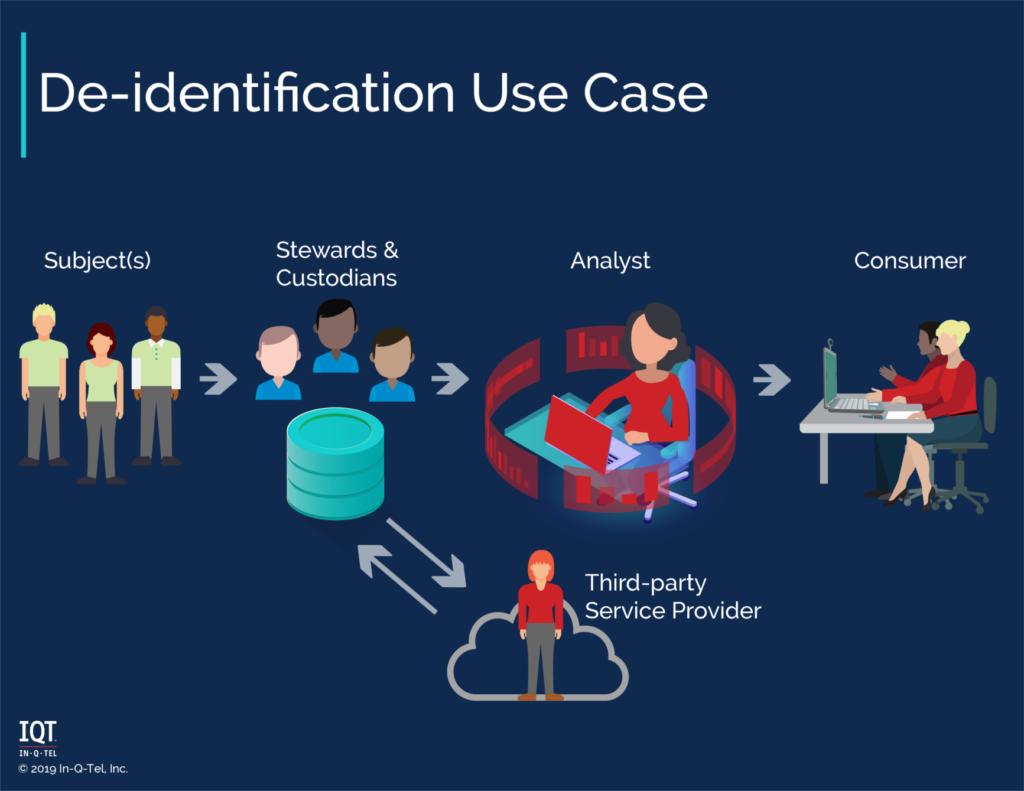
Differential privacy’s threat model is one where the person analyzing or querying the data is the threat. In this case, the analyst is allowed to access data at a high level for analysis or training a machine learning or statistical model. However, they are not allowed to access the data directly and see individual records.
Differential privacy is a mathematical definition. In practice, it means adding noise to computations or data in a way that obfuscates information about any one record while preserving the accuracy of aggregate statistics. One can add noise without the definition of differential privacy. However, that definition allows you to tune the tradeoff between noise and precise calculations. And it gives you provable guarantees about that tradeoff.
Differential privacy is good for data analysis and training machine learning models on sensitive data. In fact, some research has indicated that models trained using differential privacy generalize better.
For example, an organization is required to release a financial report monthly to the public. The report only contains aggregate statistics, such as total outlays for payroll that month.
To prepare the report, an analyst works with records showing how much each individual in the organization was paid in the last month.
Since the report only contains aggregate statistics, it is sufficiently anonymized, right? Wrong. An adversary can compare two months of records plus outside knowledge of when a particular individual was hired to infer their salary. This is called a linkage attack.
While differential privacy is good for training models, it is not good for predictions on individual records. For example, it could be used to build a model to aid medical diagnosis while keeping records private. But you could deploy that model without the differential privacy filter to get diagnosis predictions for individual patients in the field.
Homomorphic Encryption
Homomorphic encryption allows you to compute on data without decrypting it. The result of the computation is itself encrypted.
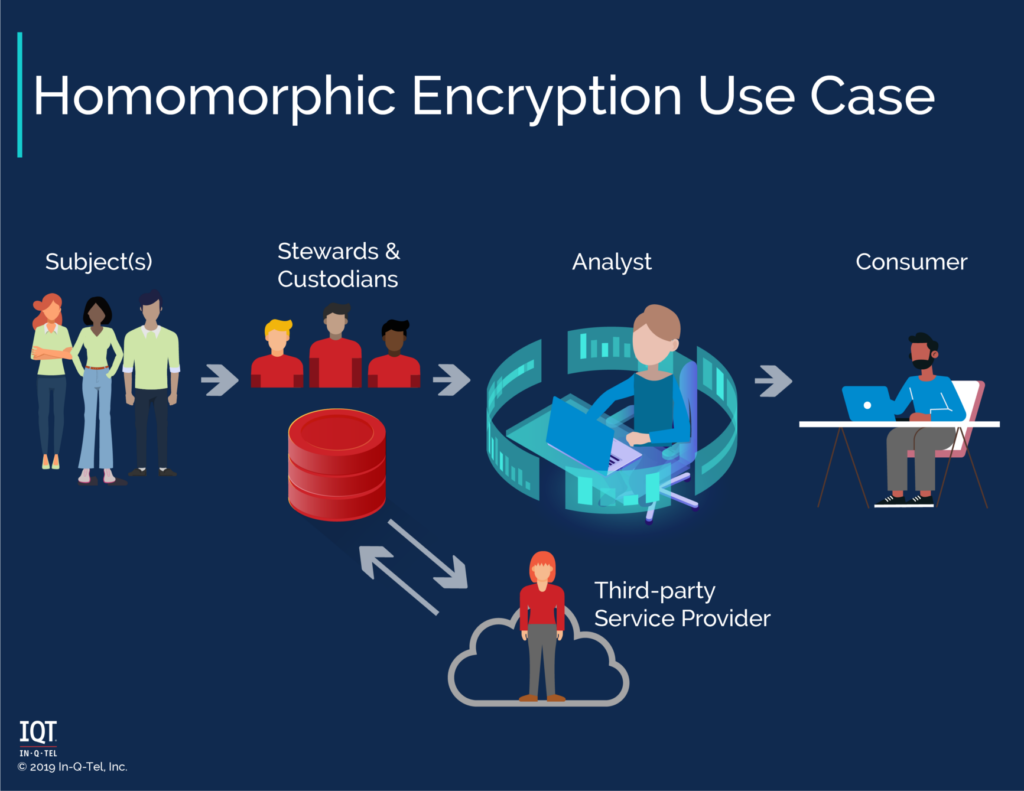
Homomorphic encryption’s threat model is one where a custodian is the threat. The custodian may not have permission to see the data and/or which operations are performed on the data. This custodian may be a database administrator or perhaps a cloud service provider.
This technology may enable IC use of cloud services. Imagine being able to use Google to translate sensitive data without Google seeing what you sent it.
Or imagine image-recognition as a service. The owner has a collection of images (i.e., subjects) and wishes to know which images contain tanks. A third-party service provider has image recognition models that can identify objects (e.g., tanks) in images. However, the images that the owner has are sensitive. To share these images with an image recognition service, would be to give the service provider a copy of the images.
Homomorphic encryption comes in two flavors: fully homomorphic and partially homomorphic. They key difference is that partial homomorphic schemes are faster, but more restrictive in the computations they support.
While a good option in some situations, homomorphic cryposystems come with inherently weaker cryptographic guarantees. And they add substantial overhead to computations.
Secure Multiparty Computation and Federated Machine Learning
Secure multiparty computation allows multiple parties to compute on a function while keeping the inputs private. This technology enables — among other things — machine learning on federated data sources. This use case is called “federated machine learning” or “federated learning.”
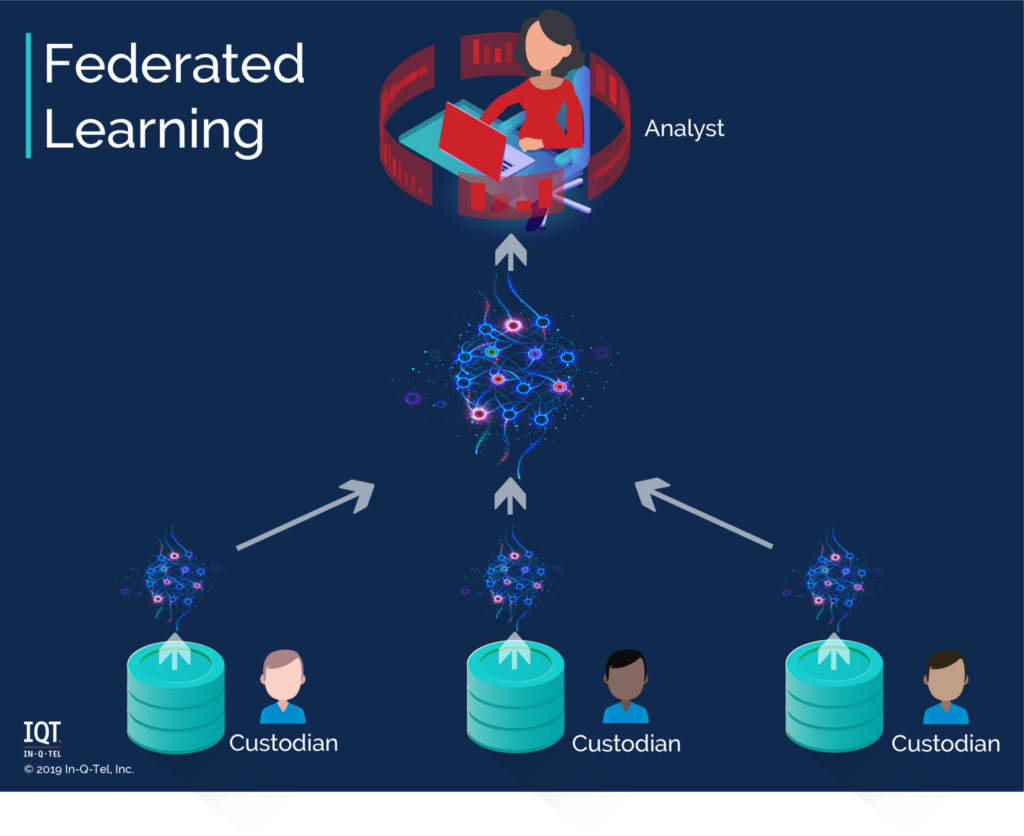
The threat model for federated learning is a little more complex. In this case you have multiple parties, each with their own data, who do not trust each other. They all want to share the output (a trained machine learning model) of a computation on all the data. Yet they are unable or unwilling to pool the data together.
For example: Bank policy and government regulations severely restrict how the most-sensitive data are handled. Several banks may benefit from a fraud detection model trained on their combined data. Yet security and privacy concerns do not allow the banks to share their data with each other. Federated learning technologies may allow them to build a common model without the data leaving their data warehouses.
Analogously, an analyst within one bank may not be able to combine data across enclaves. The data that she believes is most relevant is stored in three separate databases at three different security levels. She cannot move this most-restricted data from its system to pool it with the less restricted data.
Federated machine learning works by bringing the model to the data for training. In contrast, traditional machine learning brings the data to the model for training. Local updates to the model are made where the data is stored. Then these updates are combined in a central location to make a model using all the data.
When you have data that cannot be co-located, secure multiparty computation still allows you to use all your data.
Partial Trust Technologies and the Future of Data Privacy
We hope that this post has helped differentiate use cases for different technologies in the data privacy space. In some cases, these technologies are complimentary. For example, one can combine differential privacy and federated machine learning in a mobile product to protect individual users’ data while improving the product for all users. Hard data is difficult to come by, but our estimation is that differential privacy is being adopted slightly faster than the other two technologies.
Sharing data is a key component of getting the most out of the data organizations collect. With partial trust technologies, organizations do not have to put their customer data in potentially compromising positions. These technologies, while not silver bullets, are potentially useful steps toward ensuring data privacy while allowing for innovation from information sharing.