

Open Source Software Nutrition Labels: An AI Assurance Application

IQT Labs recently audited an open source deep learning tool called FakeFinder, which predicts whether a video contains a deepfake. This post explains how our desire to understand the risks associated with FakeFinder’s third-party software dependencies led us to create a prototype “Nutrition Label” for open source software.
If software developers and software program managers had access to information about the health and security of specific open source software packages – like shoppers in a grocery store looking at food nutrition labels – would they be empowered to make better choices about which software packages to use?

Photo by Bernard Hermant on Unsplash 
Photo by Melanie Lim on Unsplash
The Nutrition Label concept is an approach to information transparency that others in the data science, online media, and Internet of Things (IoT) communities have adapted from its original FDA context. We decided to try it out as part of our recent AI Assurance audit of FakeFinder. During that audit we examined FakeFinder from four perspectives: ethics, user experience, bias, and cybersecurity. The cybersecurity portion of the audit ( described in more detail in this post) primarily focused on trying to answer a single question from the AI Ethics Framework for the Intelligence Community:
Was the AI tested for potential security threats in any/all levels of its stack (e.g., software level, AI framework level, model level, etc.)?
In this post we explain how we built a prototype Open Source Software Nutrition Label in response to this question.
Nutrition Labels for Software Transparency
Malicious efforts to compromise software ecosystems are becoming more frequent, at least judging by reported software supply chain attacks. Consequently, itemizing package dependencies, establishing code provenance, and scanning for vulnerabilities are essential elements of modern software assurance.
Survey-based research from IQT Labs suggests that developers and data scientists tend to vet third-party packages using relatively simple heuristics instead of performing in-depth analysis. Many users also consider existing pre-install open source software package security checks inadequate.
As open source strategist Georg Link writes, “determining the health [integrity, and security] of open source projects . . . is a difficult task.” Nevertheless, we believe there are several useful proxy indicators and associated visualization techniques worth consideration. These include package contributor totals, funding resources, update recency data, and package health scores. For our prototype Open Source Software Nutrition Label, we collected and visualized several of these metrics for the FakeFinder codebase.
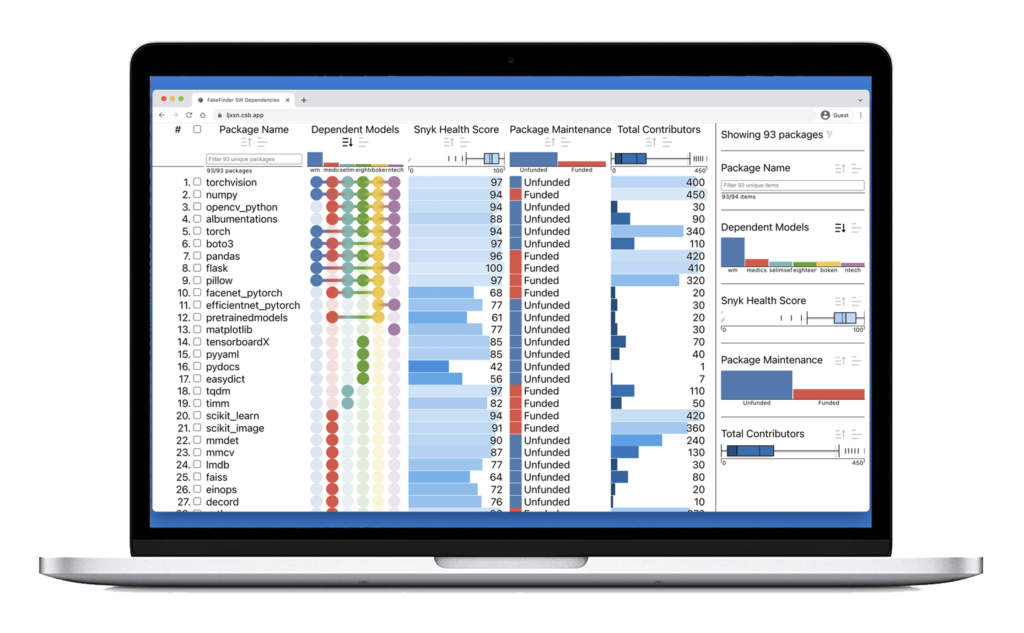
If you would like to explore the initial proofs-of-concept, check out the FakeFinder Nutrition Label. In addition, you can access the code on GitHub along with the project README, which are available to the public for reuse and modification.
Multi-Attribute Ranking of Package Dependencies
We built the Open Source Software Nutrition Label prototype using React and TypeScript in combination with a multi-attribute ranking and visualization framework called LineUp. This interface allows users to see multiple types of open source software package metadata in a single place. In addition to providing a consolidated summary of packages by name and maintenance funding status (a topic we have written about previously), the interface also shows the following metrics:
- Package Health Scores from Snyk Advisor, a general-purpose web application that provides analytics on “the overall health of a particular package by combining community and security data into a single unified” score from 0 to 100. (Snyk is not the only security tool with these capabilities, but it is among the most prominent in the PyPI, npm, and Docker communities, and it enabled us to start prototyping.)
- License Type (what licensing terms govern use/reuse of the package?)
- Total Contributors (how many GitHub user accounts have contributed commits to a particular package?)
- Total Maintainers (how many user accounts are publishing updates to the relevant package registry?)
- Total Dependencies (how many packages, in turn, does a given package dependency depend upon?)
- Total Versions (how many releases has the package undergone?)
- Days Since Last Release (when did the package last undergo maintenance?)
N.B. These values may have changed since our initial query in mid 2021, and we have not set the demo UI to refresh automatically.
Users can sort individual package dependencies based on whichever metric or combination of metrics they want to use as health criteria. You can try this capability out for yourself by opening the FakeFinder Nutrition Label and holding down the ⇧ Shift key as you click on multiple data columns (as you do in Microsoft Excel).

What we discovered
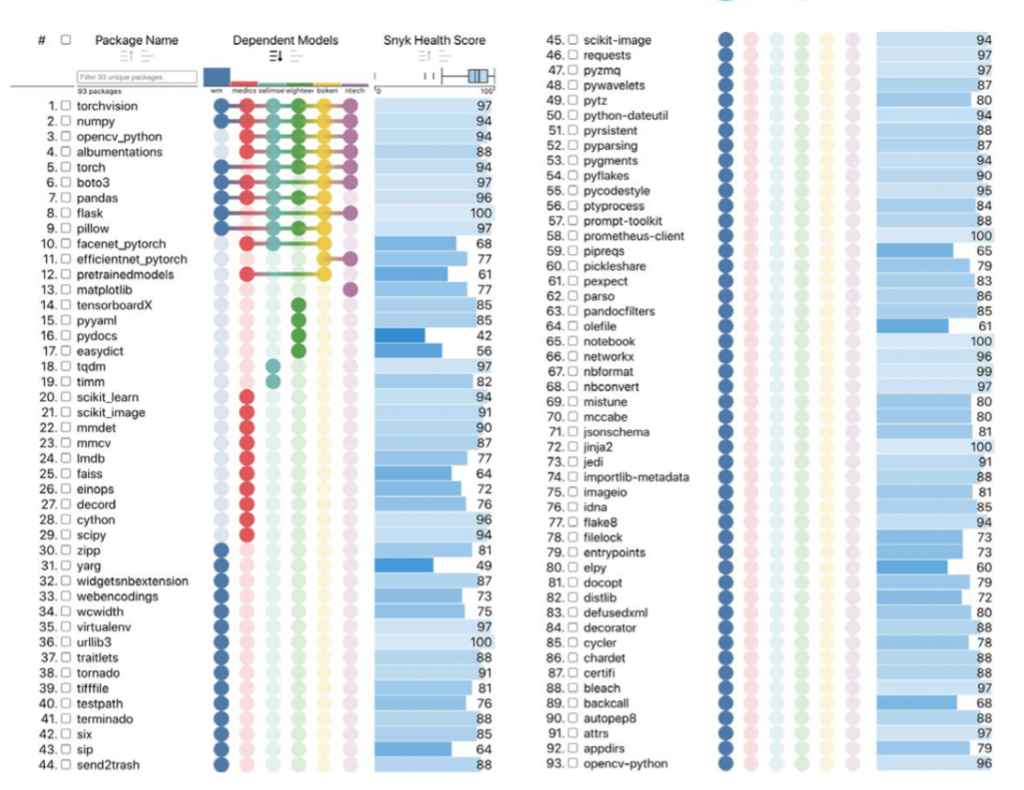
FakeFinder’s six deepfake detector models depend on 93 third-party software packages. Since these components all originated outside of IQT Labs, and since each potentially contains security vulnerabilities that may expose users to future AI software supply chain attacks, we sought to analyze the overall health of these 93 project dependencies.
In this analysis we only focused on top-level, or direct dependencies. A more thorough review would also include indirect, or transitive dependencies, which we recommend scrutinizing as well.
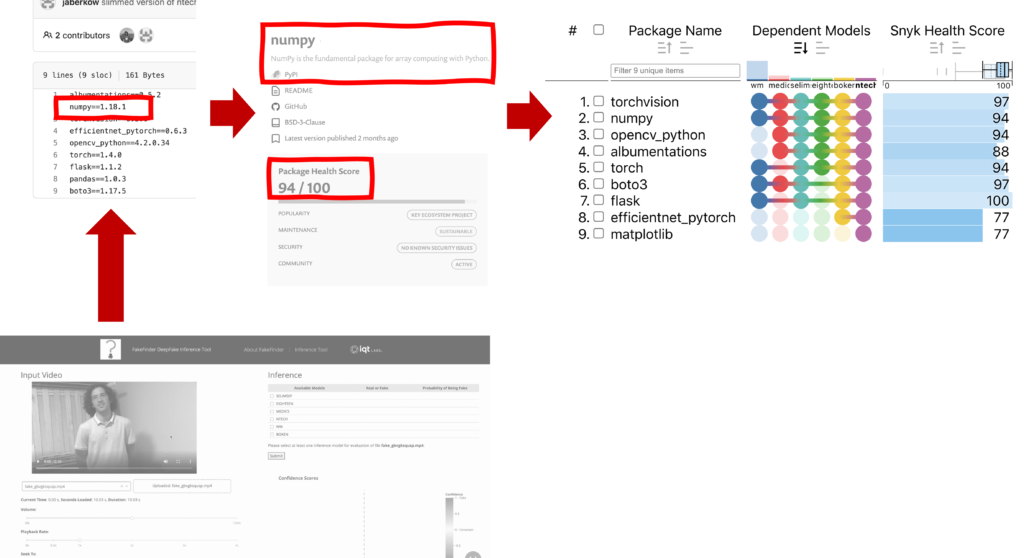
Above: a rough schematic showing our process for analyzing the dependencies of the (1) FakeFinder Deepfake Inference Tool, listed in multiple requirements.txt files (2), based on the corresponding Snyk Advisor and GitHub project metadata (3) for each dependency, and visualizing the results in the Open Source Software Nutrition Label template (4). Note the example above focuses on ntech, one of the six face swap detector models within FakeFinder.
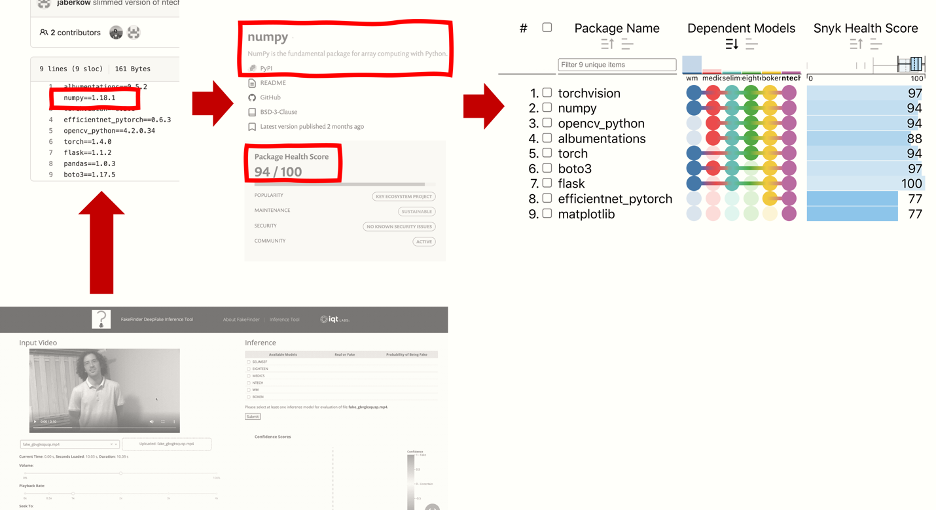
We derived a list of the FakeFinder models’ direct dependencies by combining six separate requirements.txt files from the project repository on GitHub. We then queried each dependency in Snyk Advisor, which allowed us to sort all 93 dependencies from lowest to highest score. We grouped packages by model and iterated across different versions of the Open Source Software Nutrition Label prototype, adding new columns as new metrics became available.

While this initial analysis did not raise any serious security concerns, we were able to identify a small handful of packages that warranted follow-up review based on their Snyk scores. Ultimately, the original FakeFinder team found this information helpful and actionable.
Additionally, we discovered that WM, the second-best performing model in the Deepfake Detection Challenge, was the source of over three-quarters (71/93) of all FakeFinder dependencies. In contrast, the other five models relied on substantially fewer third-party software packages. We recommend additional analysis of this model to better understand the nature of these dependencies and the business value of including WM within FakeFinder. Unless unique benefits of including WM can be demonstrated, it may not be worth the additional risk from this model’s increased attack surface.
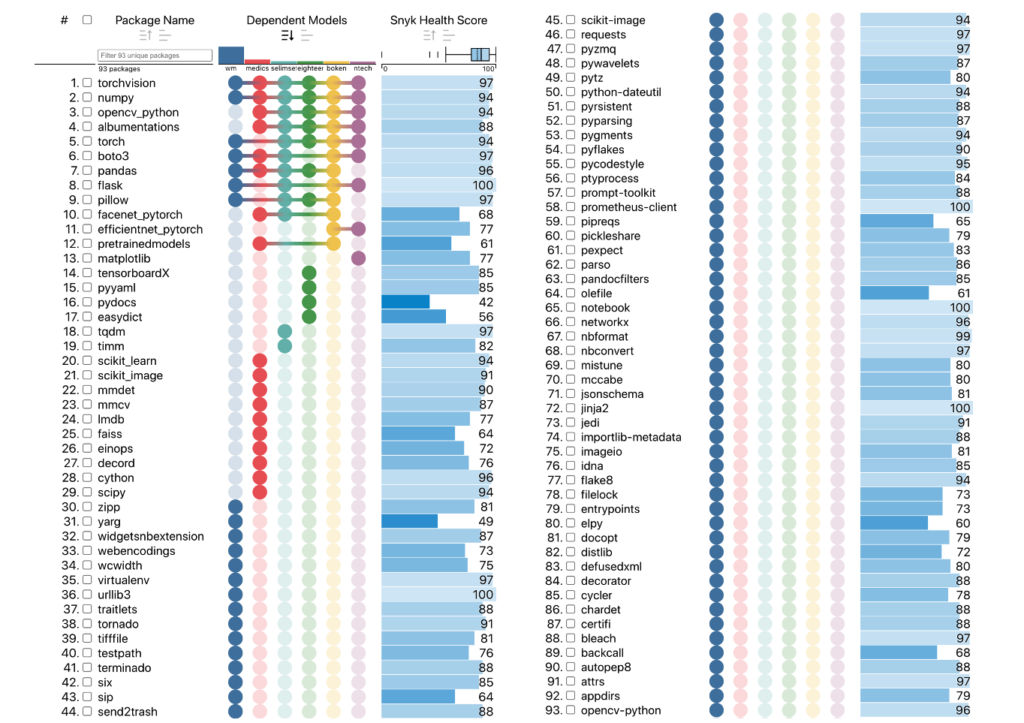
Above: Third-party software dependencies for FakeFinder’s detector models. Blue circles denote WM dependencies.
For more information on IQT Labs’ AI Assurance Audit, please contact abrennen@iqt.org or rashley@iqt.org. Anyone interested in discussing either data visualization or open source software package ecosystems should e-mail gsieniawski@iqt.org.
To Customize the Open Source Software Nutrition Label
To customize our Open Source Software Nutrition Label prototypes built in React:
- clone (or download) this repo OR fork the CodeSandbox
- modify the rows in src/data/index.tsx with your data
- update the columns in src/App.tsx with any changes to the visualization formatting
That’s it. There’s no step four, and for more details please consult the project README.
Related tools
To discover related software utilities built to support various types of open source analysis (including typosquatting checks and ecosystem assessment), try out:
- pypi-scan (CLI tool that checks for Python package misspelling attacks)
- GitGeo (CLI tool that maps GitHub committers’ self-reported locations)
- deps2repos (CLI tool that converts package lists to source code links)
- gitscrape (CLI tool that scrapes Git for data)
As we develop additional applications, resources, and datasets, please watch the IQT Labs GitHub repo for updates.
Related content and blog posts
To learn more about prior IQT Labs research that informed our work on Nutrition Labels, please check out the following related blog posts:
- “IQT Labs Presents FakeFinder, an Open Source Tool to Help Detect Deepfakes,” IQT Labs YouTube Channel, Jan. 2022
- “AI Assurance: A Deep Dive Into the Cybersecurity Portion of Our FakeFinder Audit,” IQT Blog, Jan. 2022
- “AI Assurance: What Happened When We Audited a Deepfake Detection Tool Called FakeFinder,” IQT Blog, Jan. 2022
- “Code Reuse: Holy Grail or Poisoned Chalice?” IQT Blog, July 2021
- “How Do You Dev?” Survey, IQT Labs Project Website, July 2021
- “Toward Secure Code Reuse,” IQT Blog, Feb. 2021
- “Who Will Pay the Piper for OSS Maintenance?” USENIX ;login:, June 2020
👉 Alternatively, visit high-stakes-design to see older dataviz-related posts from IQT Labs.